| БрМЭЦМі: |
БОЮФРДздгкcnblogs,ШЫЙЄЩёОЭјТчЪЧвЛжжОЕфЕФЛњЦїбЇЯАФЃаЭЃЌЫцзХЩюЖШбЇЯАЕФЗЂеЙЩёОЭјТчФЃаЭШевцЭъЩЦ.
|
|
СЊЯыДѓМвЪьЯЄЕФЛиЙщЮЪЬтЃЌ ЩёОЭјТчФЃаЭЪЕМЪЩЯЪЧИљОнбЕСЗбљБОДДдьГівЛИіЖрЮЌЪфШыЖрЮЌЪфГіЕФКЏЪ§ЃЌ ВЂЪЙгУИУКЏЪ§НјаадЄВтЃЌ
ЭјТчЕФбЕСЗЙ§ГЬМДЮЊЕїНкИУКЏЪ§ВЮЪ§ЬсИпдЄВтОЋЖШЕФЙ§ГЬ.ЩёОЭјТчвЊНтОіЕФЮЪЬтгызюаЁЖўГЫЗЈЛиЙщНтОіЕФЮЪЬтВЂЮоИљБОадЧјБ№.
ЛиЙщКЭЗжРрЪЧГЃгУЩёОЭјТчДІРэЕФСНРрЮЪЬтЃЌ ШчЙћФувбОСЫНтСЫЩёОЭјТчЕФЙЄзїдРэПЩвддкhttp://playground.tensorflow.org/ЩЯЬхбщвЛИіЧГВуЩёОЭјТчЕФЙЄзїЙ§ГЬ.
ИажЊЛњ(Perceptron)ЪЧвЛИіМђЕЅЕФЯпадЖўЗжРрЦїЃЌ ЫќБЃДцзХЪфШыШЈжиЃЌ ИљОнЪфШыКЭФкжУЕФКЏЪ§МЦЫуЪфГі.ШЫЙЄЩёОЭјТчжаЕФЕЅИіЩёОдЊМДЪЧИажЊЛњ.
дкЧАРЁЩёОЭјТчЕФдЄВтЙ§ГЬжаЃЌ Ъ§ОнСїДгЪфШыЕНЪфГіЕЅЯђСїЖЏЃЌ ВЛДцдкбЛЗКЭЗЕЛиЕФЭЈЕР.
ФПЧАДѓЖрЪ§ЩёОЭјТчФЃаЭЖМЪєгкЧАРЁЩёОЭјТчЃЌ дкЯТЮФжаЮвУЧНЋЯъЯИЬжТлЧАРЁЙ§ГЬ.
ЖрВуИажЊЛњ(Multi Layer PerceptronЃЌ MLP)ЪЧгЩЖрИіИажЊЛњВуШЋСЌНгзщГЩЕФЧАРЁЩёОЭјТчЃЌ
етжжФЃаЭдкЗЧЯпадЮЪЬтжаБэЯжГіЩЋ.
ЫљЮНШЋСЌНгЪЧжИВуAЩЯШЮвЛЩёОдЊгыСйНќВуBЩЯЕФШЮвтЩёОдЊжЎМфЖМДцдкСЌНг.
ЗДЯђДЋВЅ(Back PropagationЃЌBP)ЪЧЮѓВюЗДЯђДЋВЅЕФМђГЦЃЌетЪЧвЛжжгУРДбЕСЗШЫЙЄЩёОЭјТчЕФГЃМћЫуЗЈЃЌ
ЭЈГЃгызюгХЛЏЗНЗЈ(ШчЬнЖШЯТНЕЗЈ)НсКЯЪЙгУ.
БОЮФНщЩмЕФЩёОЭјТчФЃаЭдкНсЙЙЩЯЪєгкMLPЃЌ вђЮЊВЩгУBPЫуЗЈНјаабЕСЗЃЌ ШЫУЧвВГЦЦфЮЊBPЩёОЭјТч.
BPЩёОЭјТчдРэ
ОЕфЕФBPЩёОЭјТчЭЈГЃгЩШ§ВузщГЩ: ЪфШыВуЃЌ вўКЌВугыЪфГіВу.ЭЈГЃЪфШыВуЩёОдЊЕФИіЪ§гыЬиеїЪ§ЯрЙиЃЌЪфГіВуЕФИіЪ§гыРрБ№Ъ§ЯрЭЌЃЌ
вўКЌВуЕФВуЪ§гыЩёОдЊЪ§ОљПЩвдздЖЈвх.
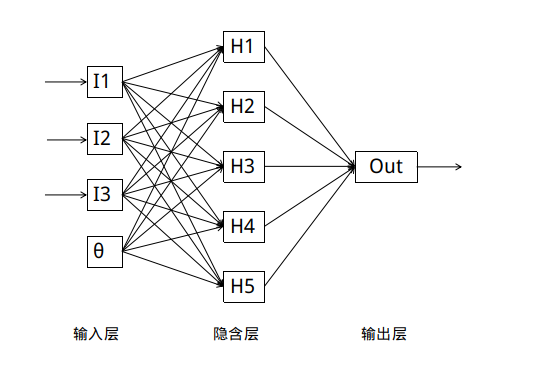
УПИіЩёОдЊДњБэЖдЪ§ОнЕФвЛДЮДІРэ:

УПИівўКЌВуКЭЪфГіВуЩёОдЊЪфГігыЪфШыЕФКЏЪ§ЙиЯЕЮЊ:
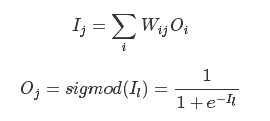
ЦфжаWijWijБэЪОЩёОдЊiгыЩёОдЊjжЎМфСЌНгЕФШЈжиЃЌOjOjДњБэЩёОдЊjЕФЪфГіЃЌ sigmodЪЧвЛИіЬиЪтЕФКЏЪ§гУгкНЋШЮвтЪЕЪ§гГЩфЕН(0ЃЌ1)ЧјМф.
ЩЯЮФжаЕФsigmodКЏЪ§ГЦЮЊЩёОдЊЕФМЄРјКЏЪ§(activation function)ЃЌ Г§СЫsigmodКЏЪ§11+e?Il11+e?IlЭтЃЌ
ГЃгУЛЙгаtanhКЭReLUКЏЪ§.
ЮвУЧгУвЛИіЭъГЩбЕСЗЕФЩёОЭјТчДІРэЛиЙщЮЪЬтЃЌ УПИібљБОгЕгаnИіЪфШы.ЯргІЕиЃЌЩёОЭјТчгЕгаnИіЪфШыЩёОдЊКЭ1ИіЪфГіЩёОдЊ.
ЪЕМЪгІгУжаЮвУЧЭЈГЃдкЪфШыВуЖюЭтдіМгвЛИіЦЋжУЩёОдЊЃЌ ЬсЙЉвЛИіПЩПиЕФЪфШыаое§;ЛђепЮЊУПИівўКЌВуЩёОдЊЩшжУвЛИіЦЋжУВЮЪ§.
ЮвУЧНЋnИіЬиеївРДЮЫЭШыЪфШыЩёОдЊЃЌ вўКЌВуЩёОдЊЛёЕУЪфШыВуЕФЪфГіВЂМЦЫуздМКЪфГіжЕЃЌ ЪфГіВуЕФЩёОдЊИљОнвўКЌВуЪфГіМЦЫуГіЛиЙщжЕ.
ЩЯЪіЙ§ГЬвЛАуГЦЮЊЧАРЁ(Feed-Forward)Й§ГЬЃЌ ИУЙ§ГЬжаЩёОЭјТчЕФЪфШыЪфГігыЖрЮЌКЏЪ§Юовь.
ЯждкЮвУЧЕФЮЪЬтЪЧШчКЮбЕСЗетИіЩёОЭјТч.
зїЮЊМрЖНбЇЯАЫуЗЈЃЌBPЩёОЭјТчЕФбЕСЗЙ§ГЬМДЪЧИљОнЧАРЁЕУЕНЕФдЄВтжЕКЭВЮПМжЕБШНЯЃЌ ИљОнЮѓВюЕїећСЌНгШЈжиWijWijЕФЙ§ГЬ.
бЕСЗЙ§ГЬГЦЮЊЗДЯђДЋВЅЙ§ГЬ(BackPropagation)ЃЌ Ъ§ОнСїе§КУгыЧАРЁЙ§ГЬЯрЗД.
ЪзЯШЮвУЧЫцЛњГѕЪМЛЏСЌНгШЈжиWijWijЃЌ ЖдФГвЛбЕСЗбљБОНјаавЛДЮЧАРЁЙ§ГЬЕУЕНИїЩёОдЊЕФЪфГі.
ЪзЯШМЦЫуЪфГіВуЕФЮѓВю:
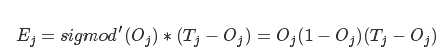
ЦфжаEjEjДњБэЩёОдЊjЕФЮѓВюЃЌOjOjБэЪОЩёОдЊjЕФЪфГіЃЌ TjTjБэЪОЕБЧАбЕСЗбљБОЕФВЮПМЪфГіЃЌ
sigmodЁф(x)sigmodЁф(x)ЪЧЩЯЮФsigmodКЏЪ§ЕФвЛНзЕМЪ§.
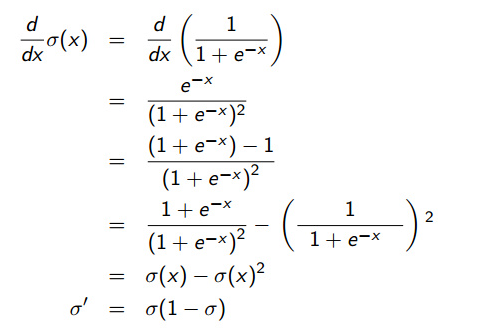
МЦЫувўКЌВуЮѓВю:
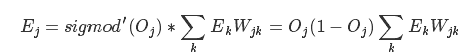
вўКЌВуЪфГіВЛДцдкВЮПМжЕЃЌ ЪЙгУЯТвЛВуЮѓВюЕФМгШЈКЭДњЬц(Tj?Oj)(Tj?Oj).
МЦЫуЭъЮѓВюКѓОЭПЩвдИќаТWijWijКЭІШjІШj:
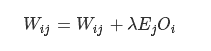
ЦфжаІЫІЫЪЧвЛИіГЦЮЊбЇЯАТЪЕФВЮЪ§ЃЌвЛАудк(0ЃЌ0.1)ЧјМфЩЯШЁжЕ.
ЪЕМЪЩЯЮЊСЫМгПьбЇЯАЕФаЇТЪЮвУЧв§ШыГЦЮЊНУе§ОиеѓЕФЛњжЦЃЌ НУе§ОиеѓМЧТМЩЯвЛДЮЗДЯђДЋВЅЙ§ГЬжаЕФEjOiEjOiжЕЃЌ
етбљWjWjИќаТЙЋЪНБфЮЊ:
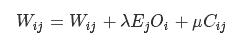
ІЬІЬЪЧвЛИіГЦЮЊНУе§ТЪЕФВЮЪ§.ЫцКѓИќаТНУе§Оиеѓ:
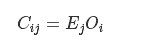
УПвЛИібЕСЗбљБОЖМЛсИќаТвЛДЮећИіЭјТчЕФВЮЪ§.ЮвУЧашвЊЖюЭтЩшжУбЕСЗжежЙЕФЬѕМў.
зюМђЕЅЕФбЕСЗжежЙЬѕМўЮЊЩшжУзюДѓЕќДњДЮЪ§ЃЌ ШчНЋЪ§ОнМЏЕќДњ1000ДЮКѓжежЙбЕСЗ.
ЕЅДПЕФЩшжУзюДѓЕќДњДЮЪ§ВЛФмБЃжЄбЕСЗНсЙћЕФОЋШЗЖШЃЌ ИќКУЕФАьЗЈЪЧЪЙгУЫ№ЪЇКЏЪ§(loss function)зїЮЊжежЙбЕСЗЕФвРОн.
Ы№ЪЇКЏЪ§ПЩвдбЁгУЪфГіВуИїНкЕуЕФЗНВю:
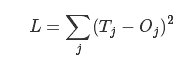
ЮЊСЫБмУтЩёОЭјТчНјааЮовтвхЕФЕќДњЃЌ ЮвУЧЭЈГЃдкбЕСЗЪ§ОнМЏжаГщГівЛВПЗжгУзїаЃбщ.ЕБдЄВтЮѓВюИпгкуажЕЪБЬсЧАжежЙбЕСЗ.
PythonЪЕЯжBPЩёОЭјТч
ЪзЯШЪЕЯжМИИіЙЄОпКЏЪ§:
def rand(aЃЌ b):
return (b - a) * random.random() + a
def make_matrix(mЃЌ nЃЌ fill=0.0): # ДДдьвЛИіжИЖЈДѓаЁЕФОиеѓ
mat = []
for i in range(m):
mat.append([fill] * n)
return mat
|
ЖЈвхsigmodКЏЪ§КЭЫќЕФЕМЪ§:
def sigmoid(x):
return 1.0 / (1.0 + math.exp(-x))
def sigmod_derivate(x):
return x * (1 - x)
|
ЖЈвхBPNeuralNetworkРрЃЌ ЪЙгУШ§ИіСаБэЮЌЛЄЪфШыВуЃЌвўКЌВуКЭЪфГіВуЩёОдЊЃЌ СаБэжаЕФдЊЫиДњБэЖдгІЩёОдЊЕБЧАЕФЪфГіжЕ.ЪЙгУСНИіЖўЮЌСаБэвдСкНгОиеѓЕФаЮЪНЮЌЛЄЪфШыВугывўКЌВуЃЌ
вўКЌВугыЪфГіВужЎМфЕФСЌНгШЈжЕЃЌ ЭЈЙ§ЭЌбљЕФаЮЪНБЃДцНУе§Оиеѓ.
ЖЈвхsetupЗНЗЈГѕЪМЛЏЩёОЭјТч:
def setup(selfЃЌ
niЃЌ nhЃЌ no):
self.input_n = ni + 1
self.hidden_n = nh
self.output_n = no
# init cells
self.input_cells = [1.0] * self.input_n
self.hidden_cells = [1.0] * self.hidden_n
self.output_cells = [1.0] * self.output_n
# init weights
self.input_weights = make_matrix(self.input_nЃЌ
self.hidden_n)
self.output_weights = make_matrix(self.hidden_nЃЌ
self.output_n)
# random activate
for i in range(self.input_n):
for h in range(self.hidden_n):
self.input_weights[i][h] = rand(-0.2ЃЌ 0.2)
for h in range(self.hidden_n):
for o in range(self.output_n):
self.output_weights[h][o] = rand(-2.0ЃЌ 2.0)
# init correction matrix
self.input_correction = make_matrix(self.input_nЃЌ
self.hidden_n)
self.output_correction = make_matrix(self.hidden_nЃЌ
self.output_n) |
ЖЈвхpredictЗНЗЈНјаавЛДЮЧАРЁЃЌ ВЂЗЕЛиЪфГі:
def predict(selfЃЌ
inputs):
# activate input layer
for i in range(self.input_n - 1):
self.input_cells[i] = inputs[i]
# activate hidden layer
for j in range(self.hidden_n):
total = 0.0
for i in range(self.input_n):
total += self.input_cells[i] * self.input_weights[i][j]
self.hidden_cells[j] = sigmoid(total)
# activate output layer
for k in range(self.output_n):
total = 0.0
for j in range(self.hidden_n):
total += self.hidden_cells[j] * self.output_weights[j][k]
self.output_cells[k] = sigmoid(total)
return self.output_cells[:] |
ЖЈвхback_propagateЗНЗЈЖЈвхвЛДЮЗДЯђДЋВЅКЭИќаТШЈжЕЕФЙ§ГЬЃЌ ВЂЗЕЛизюжедЄВтЮѓВю:
def back_propagate(selfЃЌ
caseЃЌ labelЃЌ learnЃЌ correct):
# feed forward
self.predict(case)
# get output layer error
output_deltas = [0.0] * self.output_n
for o in range(self.output_n):
error = label[o] - self.output_cells[o]
output_deltas[o] = sigmod_derivate(self.output_cells[o])
* error
# get hidden layer error
hidden_deltas = [0.0] * self.hidden_n
for h in range(self.hidden_n):
error = 0.0
for o in range(self.output_n):
error += output_deltas[o] * self.output_weights[h][o]
hidden_deltas[h] = sigmod_derivate(self.hidden_cells[h])
* error
# update output weights
for h in range(self.hidden_n):
for o in range(self.output_n):
change = output_deltas[o] * self.hidden_cells[h]
self.output_weights[h][o] += learn * change +
correct * self.output_correction[h][o]
self.output_correction[h][o] = change
# update input weights
for i in range(self.input_n):
for h in range(self.hidden_n):
change = hidden_deltas[h] * self.input_cells[i]
self.input_weights[i][h] += learn * change + correct
* self.input_correction[i][h]
self.input_correction[i][h] = change
# get global error
error = 0.0
for o in range(len(label)):
error += 0.5 * (label[o] - self.output_cells[o])
** 2
return error |
ЖЈвхtrainЗНЗЈПижЦЕќДњЃЌ ИУЗНЗЈПЩвдаоИФзюДѓЕќДњДЮЪ§ЃЌ бЇЯАТЪІЫІЫЃЌ НУе§ТЪІЬІЬШ§ИіВЮЪ§.
def train(selfЃЌ
casesЃЌ labelsЃЌ limit=10000ЃЌ learn=0.05ЃЌ correct=0.1):
for i in range(limit):
error = 0.0
for i in range(len(cases)):
label = labels[i]
case = cases[i]
error += self.back_propagate(caseЃЌ labelЃЌ learnЃЌ
correct) |
БраДtestЗНЗЈЃЌбнЪОШчКЮЪЙгУЩёОЭјТчбЇЯАвьЛђТпМ:
def test(self):
cases = [
[0ЃЌ 0]ЃЌ
[0ЃЌ 1]ЃЌ
[1ЃЌ 0]ЃЌ
[1ЃЌ 1]ЃЌ
]
labels = [[0]ЃЌ [1]ЃЌ [1]ЃЌ [0]]
self.setup(2ЃЌ 5ЃЌ 1)
self.train(casesЃЌ labelsЃЌ 10000ЃЌ 0.05ЃЌ 0.1)
for case in cases:
print(self.predict(case)) |
ЭъећдДДњТыВЮМћbpnn.py
ЪЙгУtensorflowЪЕЯжвЛИіЩёОЭјТчПЩФмЪЧИќМђЕЅИпаЇЕФЗНЗЈЃЌ ПЩвдВЮМћtensorflowШыУХжИФЯжаЕФЕкЖўНк:ЪЕЯжвЛИіМђЕЅЩёОЭјТч. |






