
前言
在我们的上一篇文章最前沿:百家争鸣的Meta Learning/Learning to learn (点击「阅读原文」获取此文)中,我们谈到了星际2 需要AI具备极好的逻辑推理能力才行,那么实际上逻辑推理这个问题学术界一直有研究,但是进展缓慢。吴恩达Andrew Ng也说过当前的深度学习技术比较适合那些对人来说可以快速解答的问题,比如说图像识别,我们不用怎么思考,语音识别,我们也不用怎么思考。但是吴恩达这么说也不完全对,比如说AlphaGo。
AlphaGo有逻辑,会推理,能思考吗?
我们都知道人类下围棋是需要思考的,那么一个不是采用穷举办法的AlphaGo能够100%碾压人类最顶尖棋手,我们也可以认为AlphaGo是有逻辑,会推理,能思考的,只不过它的思考模式和人类完全不一样。我们人类棋手下每一步棋的思考过程都是可以被记录的,但是对于AlphaGo,我们完全不知道它到底在想些什么才做出了那样的判断。我们只能认为AlphaGo在将围棋的盘面特征输入到卷积神经网络CNN的每一层的过程中完成了所谓的逻辑推理。然而我们更愿意称之为直觉Intuition,这也是deepmind官方的看法,也就是说对于AlphaGo来说,它只要凭感觉就能下棋,只不过这种感觉非常准而已。但是,
直觉可以直接等同于逻辑推理吗?
这很令人怀疑。显然,从我们人类的角度出发,我们很清楚逻辑推理是一种怎样的过程,它很大程度上是有步骤的。我们常常经过多步的思考,才做出一个决定。因此,既然让计算机能够推理是实现通用人工智能的必由之路,那么是不是可以构造一个简单一点的,但是又必须有严格的推理才能解答的问题,从而来更好的研究人工智能推理的问题。
视觉推理Visual Reasoning就是这样一个应运而生的问题!
视觉推理与CLEVER数据集
视觉推理在这里主要是限定在VQA(Visual Question Answering)的问题上,也就是让计算机看一副图,然后给出一个问题,让其回答。相比传统的VQA问题,视觉推理问题的要求是要让问题难度提升,必须经过推理才能回答。CLEVER数据集[1]就是这样一个专门针对视觉推理而诞生的数据集。CLEVER数据集是Li Fei-Fei团队做出的成果,不得不说Li Fei-Fei总是特别有远见的通过为大家贡献数据集来引领人工智能的发展。CLEVER数据集是怎样的呢?

从上图可以看到,CLEVER数据集的图都是一些简单的几何体,但是问题却复杂的多。比如说上图的第一个问题:大物体和金属球的数量是一样的吗?为了能回答这个问题,我们首先需要找出大的物体还有金属球,然后要分别计算各自的数量,最后判断两者的数量是不是相等,也就是为了回答这么一个问题,我们需要三步的推理。那么深度神经网络如果也要能做出正确的判断,我们可以认为这个神经网络经过了推理的过程,而这正是我们想要解决的。
与此同时,在传统的VQA问题上能够work的神经网络模型(CNN+LSTM)在CLEVER数据集上的表现并不好,基本上在50%的正确率,约等于瞎猜,这基本说明一般的神经网络模型并没有办法通过End-to-End端到端的训练来具备推理能力,为了在CLEVER数据集上取得好的结果,我们必须寻找新的神经网络模型。
CLEVER数据集除了提供一般的输入输出样本外,还提供了人为设计的逻辑推理过程的标签。比如说某一个问题需要三种推理过程,那么就给予三个标签。提供这些标签是为了研究人员能够基于此去探索深度学习实现逻辑推理的方法,最理想的解决方案还是要不依赖于这些标签。
CLEVER数据集是去年12月提出的,经过半年多的研究,出现了多篇论文在该数据集上取得了很不错的成果,提出了各种全新的idea。这些论文在上面列出了,下面我们就来分析一下论文的研究思路。
让神经网络生成并执行程序来实现视觉推理
首先要说的文章自然是Li Fei-Fei组的文章了:Inferring and Executing Programs for Visual Reasoning,这篇文章记得刚出来的时候引起了较大的影响,因为之前没人在VQA上这么做过。
这篇文章到底做了件什么变态的事情呢?简单的说就是传统的CNN-LSTM模型,我们是端到端训练的,输入图像,问题,然后输出答案,直接监督学习。但是这个模型不具备推理能力。所以,这篇文章就非常Naive的想:那就强制让神经网络有逻辑好了。既然我们知道CLEVER数据集上的问题是有限的,并且中间所需的逻辑推理也就是数数颜色,材质,对比数量等等几类,那么就把每一种推理作为一个Program程序,先让神经网络生成这些Program,然后再用一个神经网络来执行这个Program就行了。这确实是一个蛮酷的idea,只不过这个idea要work是有很大的前提条件的,那就是:
这么做完全是基于拥有推理的标签数据,简直就是针对CLEVER数据集弄的。
不过这个idea还是很酷啊,看图:
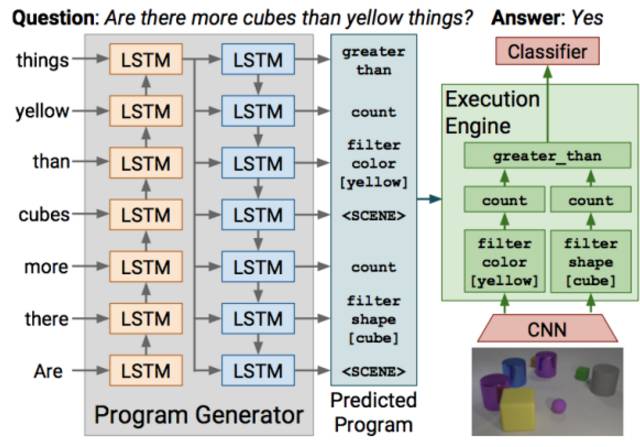
简要的说明一下这个模型,首先是一个Program Generator,就是一个Seq-to-Seq的LSTM网络,输入问题,输出预测的小程序,也就是要回答这个问题所需要的逻辑推理。接下来,图像那一边输入CNN提取特征,将小程序和图像特征放到Execution Engine也就是程序执行的地方,执行程序,最后输出到分类器输出答案。
可以看到,程序生成在有Label标签的情况下是比较容易的,直接监督学习就好了。关键是后面的程序执行引擎要怎么工作呢?
Execution Engine使用了Neural Module Networks!
Neural Module Networks是加州伯克利大学的Dan Klein团队提出的,实际上之后要讲的论文[3]也是基于这个方法来做的。Neural Module Networks顾名思义,就是将神经网络模块化,比如上图中将不同的小程序分别用一个神经网络来表示,然后根据输入的小程序,按照模块顺序串起来,输入到不同模块的神经网络中依次执行。在这篇文章中,每一个模块都是一个ResNet,并且每一个模块输出相同维度的特征Feature信息。
那么怎么来训练Execution Engine呢?
虽然Execution Engine内每一次输入的模块组合方式都不一样,但是都是端到端连接的,因此可以直接使用梯度下降训练。从这里也可以看到,这是一个完全的动态图,使用PyTorch的话就非常容易处理了。事实上文章放出的代码就是使用PyTorch来实现的。
在文章中,Program Generator和Execution Engine是先各自分开用监督学习训练,然后使用REINFORCE联合起来进一步增强。目前的VQA都已经进入到Reinforcement Learning增强学习的阶段,加了RL的方法在结果上都可以大幅度提升!
最后说一下论文的实验结果,竟然超过了人类!
虽然说利用了推理标签这种有点Cheating的手段,但是直接超过人类让人不好接受呀,只能说CLEVER数据集还是太简单了点吧。

简单评价一下这篇论文,虽然额外使用了推理监督数据,但是经过训练的神经网络实现了逻辑的可见性,也就是我们知道神经网络想的逻辑,如上图所示。由此,其实我们可以很明确的说:
神经网络是可以具备逻辑的,而神经网络不同层的输入输出就是计算机的“思考”过程。
因此,说AlphaGo的神经网络有逻辑还是说的通的。
这篇论文可以说是一小步,如果能不实现额外的监督数据就能让神经网络有逻辑那才是更好的,毕竟这种监督数据也不是那么好弄的。
使用端到端的模块化神经网络来实现视觉推理
这篇论文也就是加州伯克利的Learning to reason: End-to-end module networks for visual question answering。这篇论文因为同样是基于Neural Module Networks, 所以在方法论上和上一篇论文是非常相似的:
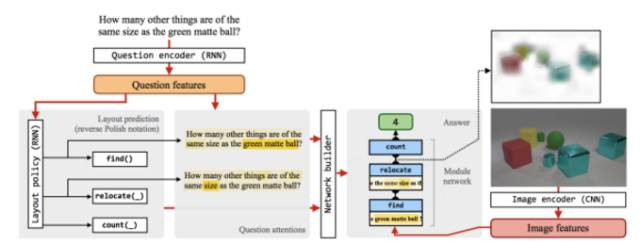
可以说前面的layout prediction和上一篇的程序生成并没有区别,是一样的,只是这里在构造网络(其实也小程序了)使用了Attention机制。使用Attention的目的实际上是为每个小程序(或者这里叫做函数指定参数)。注意上一篇论文是直接输出带参数的小程序的,这篇论文也就是将函数和参数分开生成,然后进入到Network Builder来构建整个模块化网络。剩下的训练也就差不多了。
这篇和上一篇论文在方法上曲艺同工,从实现的结果上看比上一篇差了些,可能是各种细节原因造成,这就不是非常清楚了。
使用关系网络Relational Network实现视觉推理
这篇是DeepMind的:A simple neural network module for relational reasoning
这篇论文也很酷,首先的论文的名称很酷,叫一个简单的神经网络模块来做关系推理,那么实际上确实是弄的挺简单的,如下图:
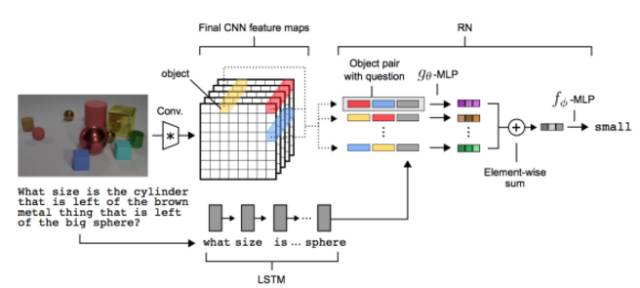
论文最核心的想法就是把CNN提出的feature特征信息当做图像中的物体来看待,然后不同物体两两组合再加上问题的LSTM输出特征,连在一起经过MLP输出一个所谓的关系feature,然后把所有的关系加在一起经过MLP输出结果!所以,这个模型真的超级简单!
但是它Work呀!
简单的评价就是:采用cnn的feature作为所谓的object竟然也能work,挺神奇的,这也说明cnn确实提取出了object的特征。RN能work说明神经网络可以任意找出两个对象之间的某种潜在关系,而这种关系可以称之为推理。
最值得注意的是这篇论文使用RN的网络结构,但是没有使用前两篇文章的额外监督数据,效果却要更好!这显然说明这篇论文的效果其实是远大于前两篇的。
前两篇论文有点像说直接跟神经网络说有这些逻辑推理,让神经网络去学,而这篇论文的思想是限定神经网络的结构,让它不得不去学习图片中不同物体的潜在关系。
但是,推理不只是关系呀,这样做依然还是有针对CLEVER数据集的嫌疑。我觉得只要把图片的场景变得复杂,甚至只要让推理的分类增大到上百类,上面这些方法都要go die!
使用Conditional Batch Normalization
这篇论文也就是这个月刚刚出炉的Learning Visual Reasoning Without Strong Priors,竟然拿到了state-of-the-art,而且只用输入输出数据训练:
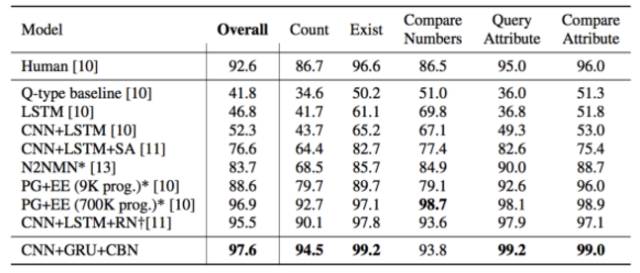
真的是很让人吃惊,这是怎么做到的呢?
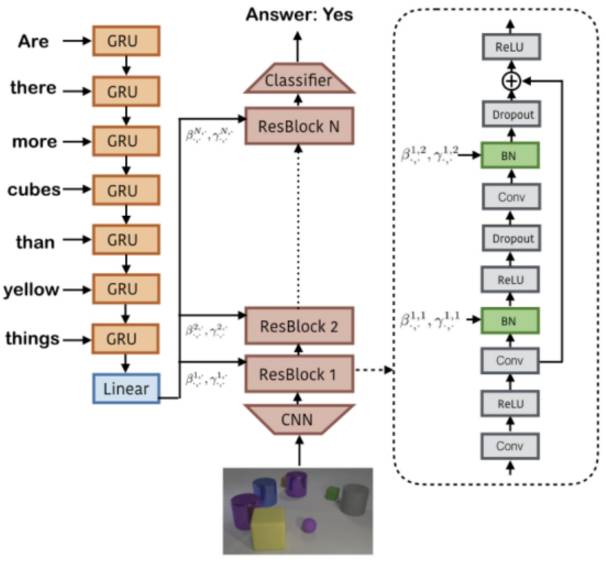
这篇论文的idea非常特别,竟然让神经网络去预测Conditional Batch Normalization的两个参数。通过调整不同的参数,我们知道会使CBN对于卷积层的处理发生变化,可以放大或者缩小不同卷积层的权重,甚至扔掉一些卷积层。
整体说一下这篇论文的model,也还是分成问题部分和图像部分。问题输入到GRU中然后输出一个特征信息e,然后用e去估计不同的ResBlock的CBN参数:
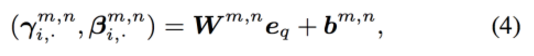
直接就是一个线性组合。
然后是图像输入部分,先用一个使用ImageNet预训练的ResNet提取出14x14的特征信息,然后输入到ResBlock中,每个ResBlock如上图所示包含了2个CBN。接下来就是把ResBlock全部连接起来,使用端到端训练。
为什么这样做能Work?
论文中对CBN的参数与推理的关系,进行了可视化:
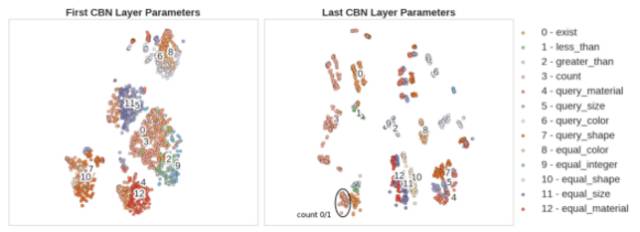
然后很神奇的发现CBN的参数和不同层级的推理是直接相关的,也就是说CBN确实自己学到了不同层次的推理。
但是,为什么通过改变CBN的不同参数对Feature Map的不同处理就能学出逻辑推理呢?论文里面也并没有明确的说明。我觉得上一篇论文的Relational Network学出一些逻辑是可以理解的,但是使用CBN并且是串联的这样也直接能学出逻辑推理能力还是很让人诧异的。这里欢迎大神来讨论一下。
小结
分析完上面的几篇前沿论文,我们可以发现研究思路可以分成两种,一种是强制让神经网络学习推理逻辑(有监督的),另一种是强制限制神经网络结构来实现无监督的学习推理逻辑。显然,第二种更强一点,但是第二种从上面看来有点针对数据集,能够构造一个更通用的神经网络结构来实现推理呢?可以拭目以待,至少从这里的分析我们可以肯定神经网络是可以有逻辑的,这是迈向“思考”的一小步啊! |






