| 前言
图像识别技术越来越多地渗透到我们的日常生活中,人可以很快递判别图像类型,比如,很容易地识别一个图片是狮子还是其它动物,可以很容易地对人脸进行识别。但是对于机器来说,去识别一个图片是什么,是一个非常困难的问题。但在过去的几年中,图像识别技术取得了巨大的进展,在一些固定领域可以达到,甚至超越人类的识别精度,该技术称为深度卷积神经网络(Deep
Convolutional Neural Network)。
目前,学术界主要通过ImageNet的Benchmark问题,去验证图像识别技术的发展程度,卷积神经网络模型包括:QuocNet,
AlexNet, Inception (GoogLeNet), BN-Inception-v2 ,以及最新的
Inception-v3 模型。其中,AlexNet的 top-5 的错误率为15.3%;Inception(GoogLeNet)降到
6.67% ;BN-Inception-v2 降到 4.9% ; Inception-v3 降到 3.46%。
如果用户有业务图片数据,如何利用开源现有的模型进行训练呢?如何进行花图片识别,人物图片识别,车辆图片识别,医学图片识别呢?本文主要介绍 TensorFlow 开源模型 Cifar10 ,Inception
V3,Vgg19的主要架构和代码。如果用户需要对业务图片识别,可再已有模型的基础上持续改进,进行训练及调优,加速研发,满足业务需求。
卷积神经网络回顾
卷积神经网络是基于人工神经网络的深度机器学习方法,成功应用于图像识别领域。CNN采用了局部连接和权值共享,保持了网络的深层结构,同时又减少了网络参数,使模型具有良好的泛化能力又较容易训练,CNN的训练算法是梯度下降的错误反向传播(Back
Propagate,BP)算法的一种变形。
卷积神经网络通常采用若干个卷积和子采样层的叠加结构作为特征抽取器。卷积层与子采样层不断将特征图缩小,但是特征图的数量往往增多。特征抽取器后面接一个分类器,分类器通常由一个多层感知机构成。在特征抽取器的末尾,我们将所有的特征图展开并排列成为一个向量,称为特征向量,该特征向量作为后层分类器的输入,如下图所示:
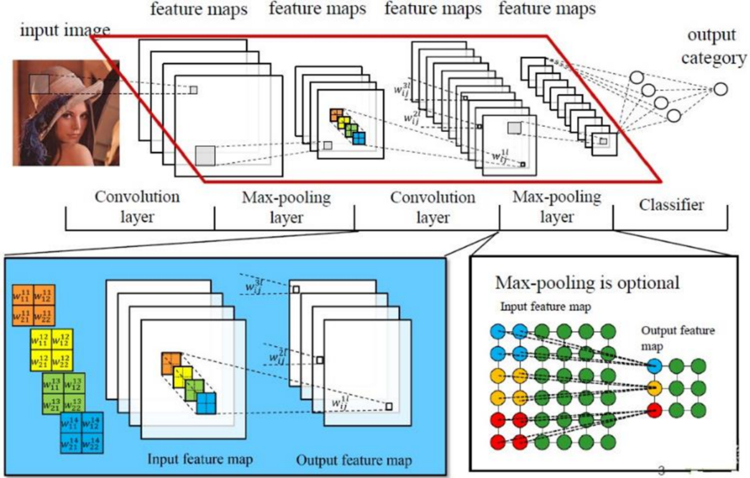
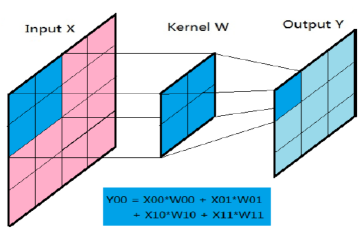
卷积过程有三个二维矩阵参与,它们分别是两个特征图和一个卷积核:原图inputX、输出图outputY、卷积核kernelW。卷积过程可以理解为卷积核卷积核kernalW覆盖在原图inputX的一个局部的面上,kernalW对应位置的权重乘于inputX对应神经元的输出,对各项乘积求和并赋值到outputY矩阵的对应位置。卷积核在inputX图中从左向右,从上至下每次移动一个位置,完成整张inputX的卷积过程,如下图所示:
子采样有两种方式,一种是均值子采样,一种是最大值子采样,如下图所示:
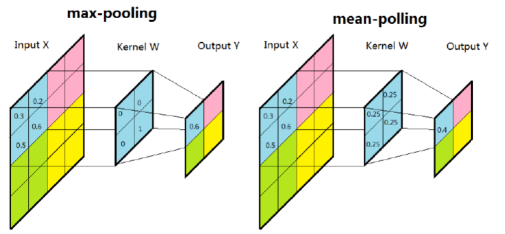
在最大值子采样中的卷积核中,只有一个值为1,其他值为0,保留最强输入值,卷积核在原图上的滑动步长为2,相当于把原图缩减到原来的1/4。均值子采样卷积核中的每个权重为0.25,保留的是输入图的均值数据。
卷积核的本质是神经元之间相互连接的权重,而且该权重被属于同一特征图的神经元所共享。在实际的网络训练过程中,输入神经元组成的特征图被切割成卷积核大小的小图。每个小图通过卷积核与后层特征图的一个神经元连接。一个特征图上的所有小图和后层特征图中某个神经元的连接使用的是相同的卷积核,也就是同特征图神经元共享了连接权重。
TensorFlow API构建卷积神经网络
在TensorFlow中,卷积神经网络( Convolutional neural networks ,CNNs )主要包含三种类型的组件,主要API如下:
卷积层(Convolutional Layer),构建一个2维卷积层,常用的参数有:
| conv
= tf.layers.conv2d(
inputs=pool,
filters=64,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu) |
inputs表示输入要的Tensor,filters表示卷积核的数量,kernel_size表示卷积核的大小,padding表示卷积的边界处理方式,有valid和same两种方式,valid方式不会在原有输入的基础上添加新的像素,same表示需要对input的边界数据进行填存,具体计算公式参见https://
www.tensorflow.org / api_docs /python/tf/nn/convolution。
activation表示要采用的激活函数。
池化层(Pooling Layer,max_pooling2d或average_pooling2d),用于构建2维池化,常用的参数有:
| tf.layers.max_pooling2d(
inputs=conv,
pool_size=[2, 2],
strides=2) |
inputs表示要被池化的输入Tensor,pool_size表示池化窗口大小,strides表示进行池化操作的步长。
全链接层(Dense Layer,dense),主要对特性向量执行分类操作。执行全链接操作前,需要对池化后的特性向量,执行展开操作,转换成 [ batch _ size ,
features ] 的形式,如下所示:
tf . reshape ( pool , [-1, 7 * 7 * 64]),-1表示 BatchSize ,
全链接层主要参数如下所示:
| tf.layers.dense(inputs=pool2_flat,
units=1024,
activation=tf.nn.relu) |
inputs表示输入层,units表示输出层的tensor的形状为
[ batchsize , units ] , activation 表示要采用的激化函数。
使用TensorFlow API构建卷积神经网络的示例代码,如下所示:
| #
输入层
# 改变输入数据维度为 4-D tensor: [batch_size,
width, height,
channels]
# 图像数据为 28x28 像素大小, 并且为单通道
input_layer = tf.reshape(features, [-1, 28,
28, 1])
# 卷积层1
# 卷积核大小为5x5,卷积核数量为32, 激活方法使用RELU
# 输入Tensor维度: [batch_size, 28, 28, 1]
# 输出Tensor维度: [batch_size, 28, 28, 32]
conv1 = tf.layers.conv2d(
inputs=input_layer,
filters=32,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
# 池化层1
# 采用2x2维度的最大化池化操作,步长为2
# 输入Tensor维度: [batch_size, 28, 28, 32]
# 输出Tenso维度: [batch_size, 14, 14, 32]
pool1 = tf.layers.max_pooling2d(inputs=conv1,
pool_size=[2, 2], strides=2)
#卷积层2
#卷积核大小为5x5,卷积核数量为64, 激活方法使用RELU.
#输入Tensor维度: [batch_size, 14, 14, 32]
#输出Tensor维度: [batch_size, 14, 14, 64]
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=64,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
#池化层2
#采用2x2维度的最大化池化操作,步长为2
#输入Tensor维度: [batch_size, 14, 14, 64]
#输出Tensor维度: [batch_size, 7, 7, 64]
pool2 = tf.layers.max_pooling2d(inputs=conv2,
pool_size=[2, 2], strides=2)
# 展开并列池化层输出Tensor为一个向量
#输入Tensor维度: [batch_size, 7, 7, 64]
#输出Tensor维度: [batch_size, 7 * 7 * 64]
pool2_flat = tf.reshape(pool2, [-1, 7 * 7 *
64])
# 全链接层
# 该全链接层具有1024神经元
#输入Tensor维度: [batch_size, 7 * 7 * 64]
#输出Tensor维度: [batch_size, 1024]
dense = tf.layers.dense(inputs=pool2_flat,
units=1024, activation=tf.nn.relu)
#对全链接层的数据加入dropout操作,防止过拟合
#40%的数据会被dropout,
dropout = tf.layers.dropout(
inputs=dense, rate=0.4, training=mode == learn.
ModeKeys.TRAIN)
# Logits层,对dropout层的输出Tensor,执行分类操作
#输入Tensor维度: [batch_size, 1024]
#输出Tensor维度: [batch_size, 10]
logits = tf.layers.dense(inputs=dropout, units=10) |
TensorFlow Cifar10模型
CIFAR-10 ,http : // www .cs . toronto . edu /~ kriz / cifar .html ,是图片识别的benchmark问题,主要对RGB为32*32的图像进行10分类,类别包括:airplane,
automobile , bird , cat , deer , dog , frog , horse , ship,
and truck。其中包括50000张训练图片,10000张测试图片。

TensorFlow Cifar10,https : / / github . com / tensorflow / models / tree / master / tutorials / image / cifar10 ,模型包含1,068,298个参数,单个图片的推导包含19.5M个乘法/加法运算。该模型在GPU上运行几个小时后,测试精确度会达到86%。模型特性主要包括:
1.核心数学组件:卷积操作,RELU激活算子,池化操作,局部响应归一化操作。
2.可视化展示:展示训练过程的loss值,梯度,以及参数分布情况等。
3.滑动平均:使用参数的滑动平均值执行评估操作。
4.预处理队列:通过队列对训练数据进行预处理,用于减少读取数据的延迟,加快数据的预处理。
该模型的代码结构如下:
1. cifar10 _ input .py:负责加载训练数据。
2.cifar10.py:负责构建cifar10模型。
3.cifar10_train.py:负责在单设备(CPU/GPU)上进行训练。
4.cifar10_multi_gpu_train.py:负责在多GPU上进行训练。
5.cifar10_eval.py:负责对模型进行评估。
该模型的Graph结构如下:

下图为Cifar10的多GPU模型架构,每个GPU型号最好相同,具备足够的内存能运行整个Cifar10模型。
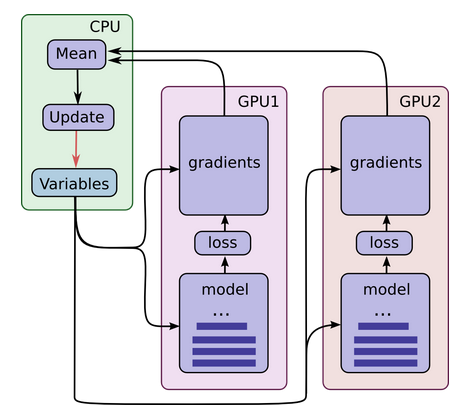
该架构会复制Cifar10模型到每个GPU上,每个GPU上训练完一个Batch的数据后,在CPU端对梯度执行同步操作(求均值),更新训练参数,然后把模型参数发送给每个GPU,进行下一个Batch数据的训练。
TensorFlow Inception V3模型
Inception V3 ,http : // arxiv . org / abs / 1512 . 00567 ,模型包含25
million个模型参数,对单个图片的推导包含了5 billion的乘法/加法运算。top-1的误差率降到了21.2%,top-5的误差率降到了5.6%。该模型网络结构如下图所示:
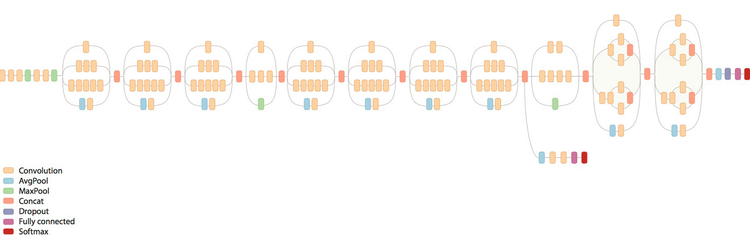
由于ImageNet的训练数据比较大,下面主要介绍如何使用Flower的数据进行训练,该数据集有5种类别(daisy,
dandelion, roses, sunflowers, tulips)的花,大概有几千张图片。
首先我们需要下载TensorFlow Inception V3模型,如下所示:
git pull https://github.com/tensorflow/models
对花数据进行训练的代码结构,如下所示:
1.data/download_and_preprocess_flowers.sh:
下载花的数据,并转换为TFRecord格式。
2.slim/inception_model.py:inception
V3模型。
3.flowers_train.py:执行单机多GPU模型的训练。
4.flowers_eval.py:对训练的准确度进行评估。
| #进入Inception
V3程序目录
cd models/inception
#设定Flower数据的存储路径
FLOWERS_DATA_DIR=/tmp/flowers-data/
#编译程序
bazel build //inception:download_and_preprocess
_ flowers
#执行下载和转换TFRecord操作
bazel-bin/inception/download_and_preprocess_
flowers "${FLOWERS_DATA_DIR}"
转换好的训练数据包括:train-00000-of-00002,train
- 0000 1- of-00002
转换好的验证数据包括:validation-00000-of-00002,
validation -00001 - of - 00002
基于训练好的Inception V3模型,继续训练花的数据:
#设定Inception V3模型下载路径
INCEPTION_MODEL_DIR=$HOME/inception- v3 - model
mkdir -p ${INCEPTION_MODEL_DIR}
cd ${INCEPTION_MODEL_DIR}
#下载训练好的Inception模型
curl -O http://download.tensorflow.org/models/
image / imagenet / inception -v3 - 2016 -
03
- 01 . tar . gz
tar xzf inception - v3 - 2016-03-01 . tar. gz
#编译程序
bazel build //inception:flowers_train
#设定要加载的模型路径
MODEL_PATH="${INCEPTION_MODEL_DIR}/inception-v3
/model.ckpt-157585"
#设定训练数据路径
FLOWERS_DATA_DIR=/tmp/flowers-data/
#执行模型训练
bazel-bin/inception/flowers_train \
--train_dir="${TRAIN_DIR}" \
--data_dir="${FLOWERS_DATA_DIR}" \
--pretrained_model_checkpoint_path="$
{MODEL_PATH}" \
--fine_tune=True \
--initial_learning_rate=0.001 \
--input_queue_memory_factor=1 |
采用单GPU,训练 1000次迭代后,模型loss值降到1.04,如下所示:

TensorFlow Vgg19模型
VGG网络与AlexNet类似,也是一种CNN,VGG在2014年的 ILSVRC localization
and classification 两个问题上分别取得了第一名和第二名。VGG网络非常深,通常有16-19层,卷积核大小为
3 x 3,16和19层的区别主要在于后面三个卷积部分卷积层的数量。可以看到VGG的前几层为卷积和maxpool的交替,后面紧跟三个全连接层,激活函数采用Relu,训练采用了dropout。VGG中各模型配置如下,
其中VGG19的top-1的训练精度可达到71.1%,top-5的训练精度可达到89.8%。模型结构示例如下:

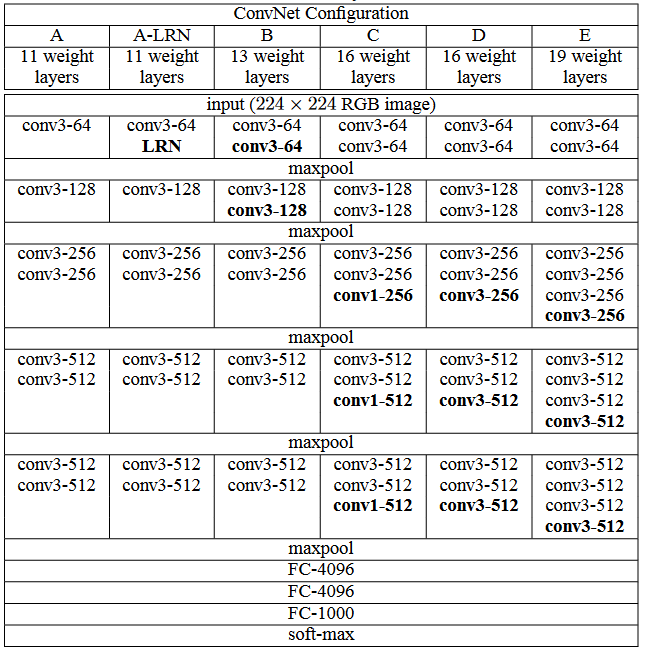
TensorFlow Vgg19的模型示例如下,https : /
/ github . com / tensorflow / models / blob / master
/ slim / nets / vgg . py :
| #卷积操作和池化操作
net = slim.repeat(inputs, 2, slim.conv2d, 64,
[3, 3], scope='conv1')
net = slim.max_pool2d(net, [2, 2], scope='pool1')
net = slim.repeat(net, 2, slim.conv2d, 128,
[3, 3],
scope='conv2')
net = slim.max_pool2d(net, [2, 2], scope='pool2')
net = slim.repeat(net, 4, slim.conv2d, 256,
[3, 3],
scope='conv3')
net = slim.max_pool2d(net, [2, 2], scope='pool3')
net = slim.repeat(net, 4, slim.conv2d, 512,
[3, 3],
scope='conv4')
net = slim.max_pool2d(net, [2, 2], scope='pool4')
net = slim.repeat(net, 4, slim.conv2d, 512,
[3, 3],
scope='conv5')
net = slim.max_pool2d(net, [2, 2], scope='pool5')
net = slim.conv2d(net, 4096, [7, 7], padding=fc_
conv_padding, scope='fc6')
#dropout操作,防止过拟合
net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
scope='dropout6')
net = slim.conv2d(net, 4096, [1, 1], scope='fc7')
net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
scope='dropout7')
net = slim.conv2d(net, num_classes, [1, 1],
activation_fn=None,
normalizer_fn=None,
scope='fc8') |
总结
本文首先回顾了深度卷积神经网络的特征图、卷积核,池化操作,全链接层等基本概念。接着介绍了使用TensorFlow
API构建卷积神经网络,主要包括卷积操作API,池化操作API以及全链接操作API。针对图片识别,讲解了TensorFlow
Benchmark模型( Cifar10 ,Inception V3及Vgg19)的架构和代码。如果有用户需要对自己的业务图片进行识别,可再已有模型的基础上持续改进,进行训练及调优,加速研发。 |






