| 这篇文章陈述如何用关系型数据库实现UML模型。假设我们熟悉UML对象建模表示法和关系型数据库。 许多人认为面向对象概念和关系型数据库相互不一致,并且不能结合。事实上完全相反!经过灵活的使用,一个关系型数据库能够为面向对象(OO)模型提供一套优秀的实现。同样的模型能够用来开发编程代码和建立关系型数据库结构。 关系型数据库技术是意义深远的、强大的,但它比许多开发商使你相信的要难得多。单个表是简单易懂的、直观的,但是要彻底了解由数以百计的表组成(这是常见的)的应用是相当困难的。这正是OO模型有用之处。 OO模型使你深入地、连贯地思考问题。OO模型提供一种问题的超结构(superstructure)的思考方式,然后该方式能够用关系型数据库的更低层的组成块来实现。 本文章综合地讨论了关系型数据库技术,而不是集中于特定的产品上。我们将不讨论物理设计细节(例如存储分配和物理聚集),因为它们是依赖于产品的。 用关系型数据库实现UML模型有两个方面:映射结构(第2节)和映射功能(第3节)。第4节注解了面向对象到关系型数据库的扩展。第5节总结本文章。 UML对象模型在本质上只是一个扩展的实体-关系(ER)模型[ii]。用来设计数据库的ER模型的方式受到普遍接受,而我们将讲述一种近似的但更强大的方式-使用UML对象模型。OO模型的主要优势在于编程和数据库使用相同的模型工作。而且,作为考虑功能性的一种方式(第3节),我们强调OO模型的导航。这一节显示如何实现UML对象模型的主要构造。 实现对象模型的第一步是处理标识。我们从定义几个术语开始。
正常地你应该为每个表定义一个主键,尽管偶尔有例外。我们强烈建议所有的外键都只指向主键而不是其它的候选键。 定义主键有两种基本的方法:
我们推荐你在超过30个类的RDBMS应用里使用基于存在的标识。基于存在和基于值的标识都是所有RDBMS应用的可行选项。 属性类型是UML术语,对应于数据库著作里的域的术语。比起直接用数据类型,域提升到更一致的设计,并便利了应用的定位。 简单域很容易实现。你仅仅要定义相应的数据类型和大小。并且每个用了域的属性,你都必须为每个域约束加入一条SQL检查子句。简单域的一些例子是:名字(name),长字符(longString)和电话号码(phone-Number)。 一个枚举域把一个属性限制在一系列的值里。枚举域比简单域实现起来更复杂,图1显示了四个方法。
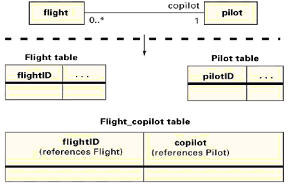
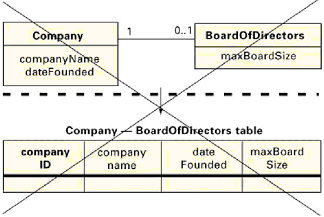
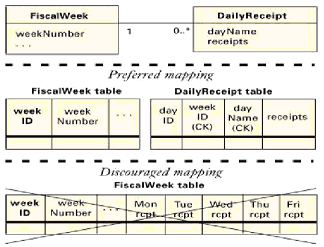
正常情况下,我们把每个类映射为一个表,每个属性映射为一个列。你可能因一个已产生的标识符(基于存在的标识符)、隐藏的关联(第2.4节)和通用鉴别器(第2.5节)需要一些另外的列。 现在我们讨论关联的实现。我们已经把我们的陈述分为建议的映射(我们正常使用的映射),可选的映射(我们偶尔使用的映射)和不鼓励的映射(我们遇到的应该避免的错误)。我们所有的例子都采用基于存在的标识。
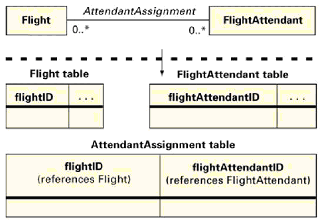 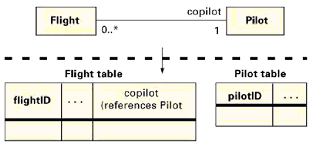 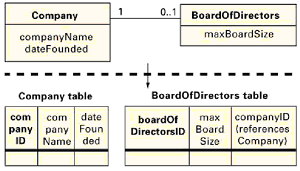 正常情况下我们使用建议的映射。但有些偶尔的情况,可选的映射更合适。
我们已经注意到有些开发者选择有缺陷的映射。我们要注意避免这些映射。
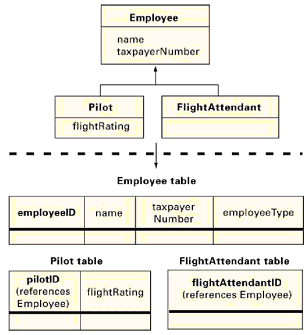
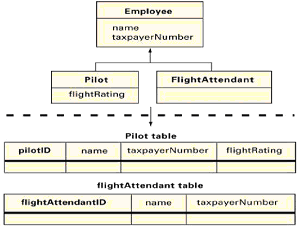
    现在我们讨论泛化。我们这里只论述单个继承。 最简单的方法是只映射超类和每个子类为一个表。所有的表共享一个共同的主键。应用必须执行子类的划分,因为RDBMS并不能执行。(关于后者的详尽的描述,请参阅第4节。)
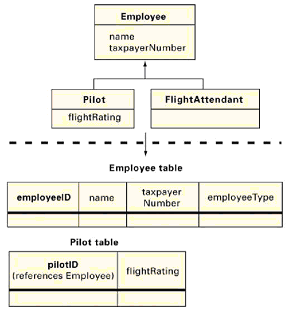
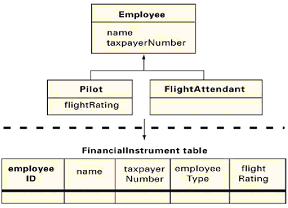
 泛化有几个可选的映射。
   一旦你已经建立了表,你就应该定义参考完整性动作来明确对象模型的意义。(不要使用SQL触发器来实现参考完整性!)如果你使用基于存在的标识,你将不需要传播更新的结果。我们建议以下对删除的参考完整性方针:
我们已经简要地论及参考完整性,因为它是个高级话题。参考文献[iii]有更多的解释和例子。 实现数据库结构的最后的一步是加入索引来调整数据库性能。正常地,你应该为每个主键和候选键定义一个唯一的索引。(多数RDBMS作为SQL主键和候选键约束的副作用来建立唯一的索引。)你也应该为每个被主键或候选键所约束的外键建立一个索引。 我们强调索引的重要性。外键和主键的索引使在对象模型里能快速地遍历是不容怀疑的。你必须包括这些索引,否则你将使用户感到灰心。你应该在你的数据库开始设计阶段里加入索引,因为它们很容易加入并且也没有什么好理由推迟加入。 数据库管理员(DBA)可能为经常请求的查询定义了额外的索引。DBA也可能采用产品相关的调整性能的机制。 范式是关系型数据库设计的提高数据一致性的有效方法。我们的书3讨论了范式,但我们关于这个问题却说错了。我们将利用这篇文章的机会来澄清我们的观点。如果你不熟悉范式你可以跳过这节。我们的说明是针对关系型设计人员,他们正在尝试用面向对象适应他们原有的技能。 范式是正确设计关系型数据库的精确的原则。同样地,它们与使用了什么开发技术是无关的 - 基于属性的设计、基于实体的设计、面向对象设计或其它什么。 过去使用基于属性设计的方法,开发人员不得不非常注意范式;范式提供了分组数据的根据。相反地,范式对于基于面向对象(或基于实体)的开发不是很重要。如果你采用OO方法并且你的模型经过很好的构思,那你就正在把数据组织成为有意义的单位,也在本质上满足了范式的规定。如果你愿意,你仍能够检查范式,但这样的检查是不必要的。 图13总结了我们已经陈述的映射规则。这些映射规则的完整例子,包括一个UML对象模型,能够在这篇完整的扩展版本里找到(Adobe Acrobat PDF文件)。
对象模型为数据库应用提供三种主要的用途。
对象模型不仅仅是被动的数据结构,相反它们能够帮助你思考一个应用的功能。你可以根据遍历一个对象模型说出它的许多功能。例如,根据我们对一个模型检查用例时的遍历,我们进行思索。这强调对象模型的估算能力对于RDBMS应用是特别重要的,因为遍历表达式可以直接映射到SQL代码。 UML对象约束语言(Object Constraint Language,OCL)有助于表达遍历。点符号导航从对象到对象和对象到属性,方括号表示对象集合的过滤器。我们加入冒号(:)操作符来表示泛化的遍历;因为我们正常地用多个表来实现一个泛化继承,清楚的遍历很有用。 图14里的遍历表达式例子是基于我们创建的UML对象模型上的(请参阅本文的扩展版本(Adobe Acrobat PDF文件)),我们把它们映射为SQL代码。我们用冒号开始SQL编程变量。
数据库团体对RDBMS的OO扩展有兴趣。产品和SQL标准正尝试加入到OO扩展里。我们将简要地陈述一下这个技术的方向。
图15摘录于我们的在参考文献3的财务案例学习。我们用资产超类来统一某些没有显示在摘录里的通用的数据和功能。一项资产可以是一支股票或股票期权。一支股票可以有许多它的股票期权。例如,IBM股票可以有许多写明达到价格和过期日期的期权。 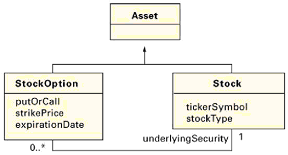 我们推荐的泛化实现是单独的表 - 映射该超类和每个子类为一个表。然后,我们就可以使用参考完整性使股票期权和股票的记录依赖于资产。一个资产记录的删除级联到相应的子类记录、股票期权或股票的删除上。我们也能够定义一个参考完整性动作,这样一个股票的删除就级联到关联的股票期权记录的删除。 现在问题如下:如果我们删除的一项资产是一支股票,资产记录的删除级联到引起股票记录的删除。随后,股票记录的删除级联引起所有股票期权记录的删除。但现在参考完整性使我们失败了:一条股票期权记录的删除并不引起一项资产记录的删除。删除级联只能从超类走到子类。为了完全的行为,级联应该双向地走下去。 当前有用的参考完整性的工作是做更多的编程(也即做更多的工作和承担更多的故障风险)。在我们的案例学习的实现里,用户随时要删除一项是股票的资产,我们不得不书写额外的代码来首先检查关联股票期权的存在性,然后删除它们。
本文陈述了用关系型数据库实现UML模型的快速的概观。我们希望本文向你演示的技术是十分适用的。一个训练有素的开发人员能够用关系型数据库准备一套优秀的OO模型的实现。如果你要关于实现机制的更多的细节,参考3有另外的信息,并且也覆盖了我们没有在这里讨论的一些高级模型建模结构。 Michael Blana是纽约Schenectady的通用电气研发部的毕业生(译者按:这是作者幽默的说法,意思是他已经跳槽了)。在过去的五年里,他已经成为面向对象技术、建模、数据库设计和逆向工程领域的独立的产业顾问。Blaha博士是多篇论文、五个专利和两本书的作者。可以通过www.omtassociates.com或blaha@acm.org和他联系。 William Premerlani从1975年开始就在通用电气研发部供职。他的主要研究兴趣在软件工程、元建模(metamodeling)、数据库技术和复杂工程应用等领域。Premerlani博士是许多论文、二十五个专利和两本书的作者。通过premerlani@acm.org和他联系。 [i]Michael Blaha and William Premerlani. Object-Oriented Design of Database Applications. Rose Architect 1,2 (Winter, 1999). [ii] PPS Chen. The Entity-Relationship model - toward a unified view of data. ACM Transactions on Database Systems1, 1 (March 1976). [iii] Michael Blaha and William Premerlani. Object-Oriented Modeling and Design for Database Applications, Prentice Hall, Englewood Cliffs, New Jersey, 1998. [iv] CJ Date. Don't mix pointers and relations! Presentation at Third Annual Object/Relational Summit sponsored by Miller Freeman, Washington D.C., September 16-19, 1998. |