排错(即调试)与成功的测试形影相随。测试成功的标志是发现了错误。根据错误迹象确定错误的原因和准确位置,并加以改正的主要依靠排错技术。
1. 排错过程
如下图所示,排错过程开始于一个测试用例的执行,若测试结果与期望结果有出入,即出现了错误征兆,排错过程首先要找出错误原因,然后对错误进行修正。因此排错过程有两种可能,一是找到了错误原因并纠正了错误,另一种可能是错误原因不明,排错人员只得做某种推测,然后再设计测试用例证实这种推测,若一次推测失败,再做第二次推测,直到发现并纠正了错误。
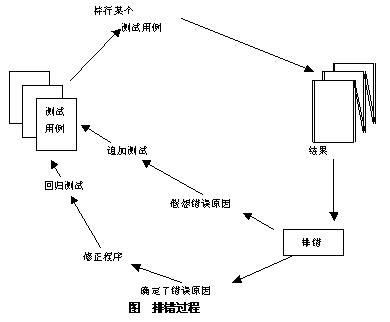
排错是一个相当艰苦的过程,究其原因除了开发人员心理方面的障碍外,还因为隐藏在程序中的错误具有下列特殊的性质:
(1) 错误的外部征兆远离引起错误的内部原因,对于高度耦合的程序结构此类现象更为严重;
(2) 纠正一个错误造成了另一错误现象(暂时)的消失;
(3) 某些错误征兆只是假象;
(4) 因操作人员一时疏忽造成的某些错误征兆不易追踪;
(5) 错误是由于风时而不是程序引起的;
(6) 输入条件难以精确地再构造(例如,某些实时应用的输入次序不确定);
(7) 错误征兆时有时无,此现象对嵌入式系统尤其普遍;
(8) 错误是由于把任务分布在若干台不同处理机上运行而造成的。
在软件排错过程中,可能遇到大大小小、形形色色的问题,随着问题的增多,排错人员的压力也随之增大,过分地紧张致使开发人员在排除一个问题的同时又引入更多的新问题。
尽管排错不是一门好学的技术(有时人们更愿意称之为艺术),但还是有若干行之有效的方法和策略,下面介绍几种排错方法。
2. 排错方法
无论采用哪种排错方法,目标只有一个,即发现并排除引起错误的原因,这要求排错人员能把直观想象与系统评估很好的结合起来。
常用的排错策略分为三类:
① 原始类(brute force)
② 回溯类(backtracking)
③ 排除类(cause eliminations)
原始类排错方法是最常用也是最低效的方法,只有在万般无奈的情况下才使用它,主要思想是“通过计算机找错”。例如输出存储器、寄存器的内容,在程序安排若干输出语句等,凭借大量的现场信息,从中找到出错的线索,虽然最终也能成功,但难免要耗费大量的时间和精力。
回溯法能成功地用于程序的排错。方法是从出现错误征兆处开始,人工地沿控制流程往回追踪,直至发现出错的根源,不幸的是程序变大后,可能的回溯路线显著增加,以致人工进行完全回溯到望而不可及。
排除法基于归纳和演绎原理,采用“分治”的概念,首先惧与错误出现有关有所有数据,假想一个错误原因,用这些数据证明或反驳它;或者一次列出所有可能的原因,通过测试一一排除。只要某次测试结果说明某种假设已呈现倪端,则立即精化数据,乘胜追击。
上述每一类方法均可辅以排错工具。目前,调试编译器、动态调试器(“追踪器”)、测试用例自动生成器、存储器映象及交叉访问示图等到一系列工具已广为使用。然而,无论什么工具也替代不了一个开发人员在对完整的设计文档和清晰的源代码进行认真审阅和推敲之后所起的作用。此外,不应荒废排错过程中最有价值的一个资源,那就是开发小组中其他成员的评价和忠告,正所谓“当事者迷,旁观者清”。
前面多次提到,修改一处老问题可能引入几处新问题,有时程序越改越乱,但若能做到每次纠错前都扪心自问三个问题,情况将大为改观:
① 导致这个错误的原因在程序其他部分还可能存在吗?
② 本次修改可能对程序中相关的逻辑和数据造成什么影响?引起什么问题?
③ 上次遇到的类似问题是如何排除的?