��Ȩ���������ĵķ���û�л�����ߵ���Ȩ��������ƪ���Ľ���Ϊѧϰʹ�á���ֹ�κ���ת�ش��Ļ���Ϊ��ҵ��;��������κ�����Ϊ��ƪ�����ַ������Ȩ���������Ÿ������ǡ� 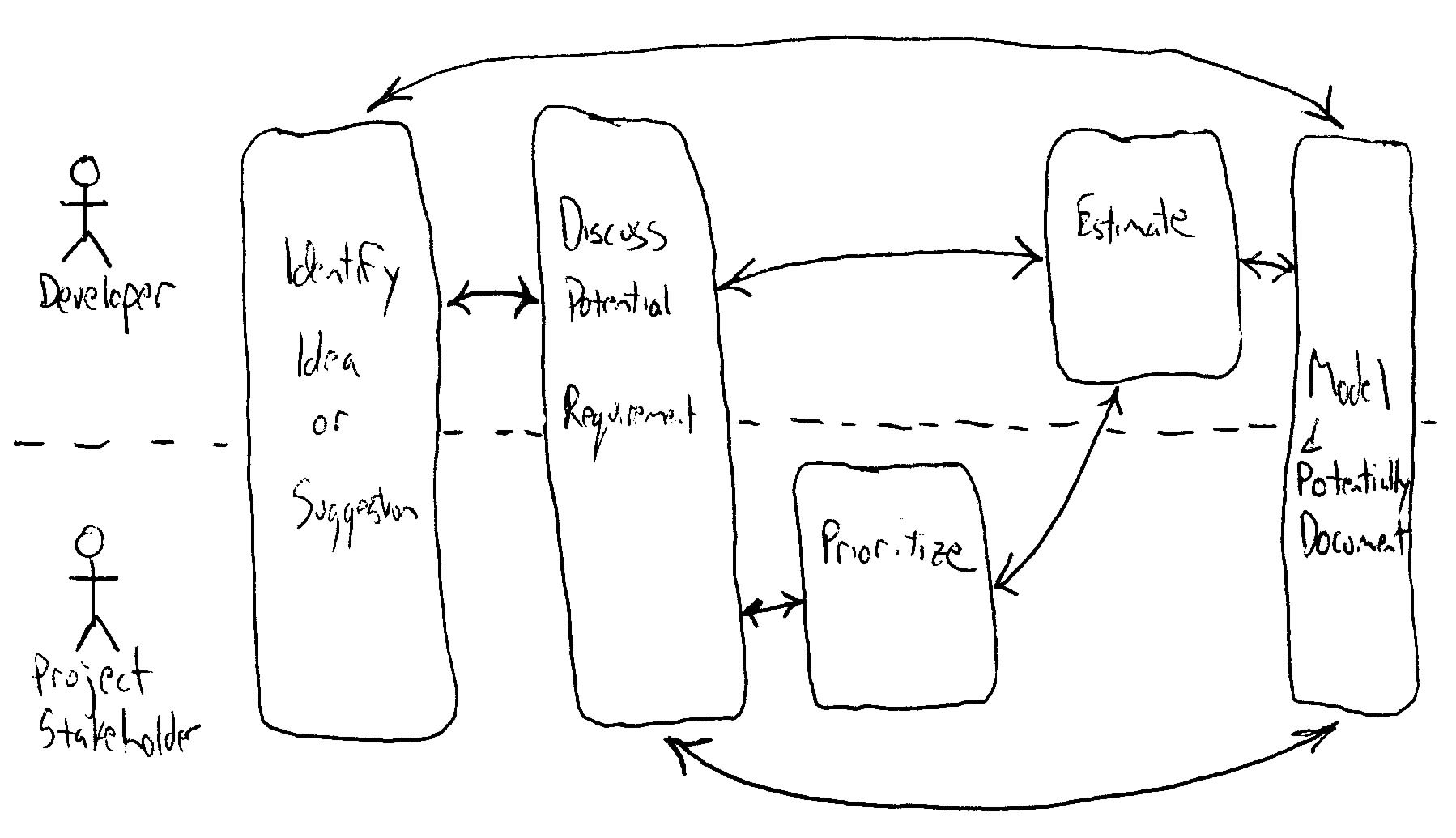 �ҵ���ѧ����Ϊ��Ŀ����Ӧ�ò�������Ľ�ģ���ĵ��������ǽ���ͣ�����ṩ��Ϣ�ĽΣ�����Ӧ�ò��뵽�����������ǵģ���Ҫ����Ա��һЩ��ѵ��ָ����ѵ�������Ⲣ���Dz���ʵ�ֵġ��Ҿͼ�����Ŀ���ڵĽ�ģ���ĵ����ķdz��õģ�����������Ŀ�鲼�ڲ�ͬ��ģ����֯�У�С�͵ĸ��Ĺ�˾��������ҵ�����������У���Խ�����ҵ�����š����ڡ����졢���¡�Ϊʲô��һ���ر���Ҫ�أ���Ϊֻ�������Ŀ���ڲ�������ġ�ר�ҡ����������������Ҫʲô������ֻ�����Թ��������ǿ���ѧ�����Ϊ����ģ�ͱ����ĵ��ġ�������ݵĹ۵�������Ҳ���е����ģ����ѽ�ģ��Ŭ�����ɾͷֵ��˸����˵�ͷ�ϡ� Ϊ��ʹ��Ŀ���ڸ����ġ��������ļ��뵽����ģ�������ĵ����Ļ������Ϊ�˼�����ҵ�����γɵĸ��ң�����Ҫ����һ��ʵ����ʹ�ü��ߡ��ڱ���1���г��ĺܶ������Ľ�ģ����ʹ�üĹ��ߣ�Ҳ����ʹ�ø��ӵĹ��ߣ���һ���оٳ���ÿһ�������ļ��ߡ�ͼ2��ͼ3��������չʾ������ʹ�ü��߽�����ģ�͡�ͼ2��ʹ����ʹ���˼�ʱ���ͻ��ͼ����������ģ�ͣ���ͼ3ʹ��������Ƭ�����и��ģ��ֻҪ��������ģ��ʹ�����µļ���������ʹ�û�ͼ��������������ͼ�ĸ����汾������ʹ�ù��ܶ���CASE���ߣ���ͻ��������н������Ŀ�����ų����⣬��Ϊ���Dz���Ҫѧϰ��ģ������Ҫѧϰ��ģ���ߡ������ּ�������������˴�ҵIJ��룬Ҳ��������Ч�����Ļ��ᡣ  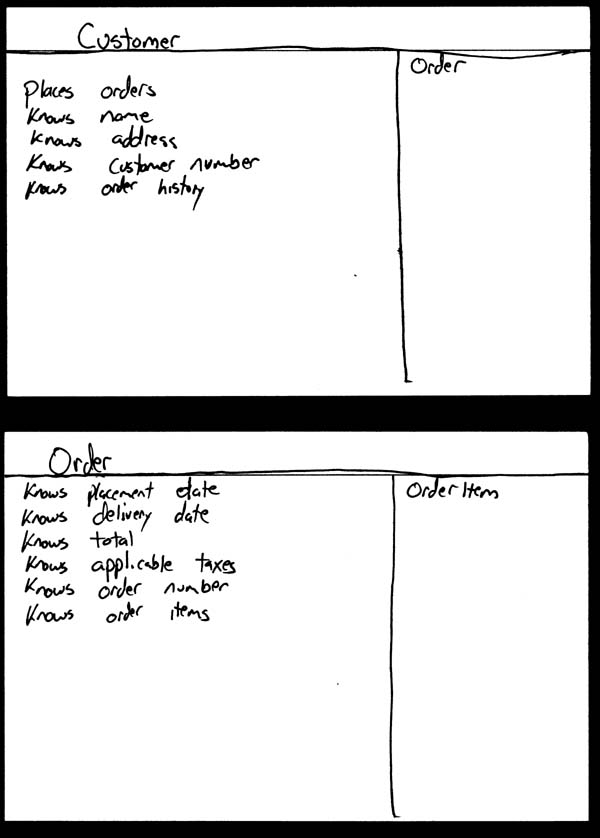 ���������������Ǻͼ����صġ���������������������ṹ�����������ǻ����������֮��������ʱ���������ѡ���Щ���������ṹ�����������������ʵ�ּ����ķ��ࡣ��Ȼ����Դ���Щ�����ѡȡһ����ʵ�֣������Ҳ�������㣬�������٣������Ҫ�����������ԣ�ֻ�����������������������еļ�����������Ϊ��Щ����ϵͳ��������ģ�͵ġ� ��ʱ�������û�а취���������ص��������磬���������Ŀ������һ���ձ�����ƣ����Dz��ۿ�����������������еļ������ܡ���ʵ�����������ϣ��������Ǽ����صģ����������Ҫ���ȥ����ʼ�г�һ�����й��ܵ�����嵥��ʱ��D���磬���your Sybase vX.Y.Z ���ݿ�������������һ�����е�SAP R/3ģ��D������ˡ�ֻҪ�㶮�ø���ʲô�Ͳ�����ʲô��OK�ˡ� ʼ���μǣ���Ƭ״˼������СƬ���������繦�ܣ�features�����زģ�user stories����Ҫ�ȴ��͵���������������use case����������Ԥ����ƽ��ÿһ�����������Ĺ�����Ҫ���زĶ࣬����������Ϊ����Ҫ����һЩ�� ͬ��������Ͷ�ʽ�������ɸ��پ���֮ǰ��ҲҪ����������ɸ������Ǹ��������Ŀ������ϵ��һ���һ��������������ɸ��پ������һ�ֱ�������¼������ϵ�Ĺ���������ʼ����Ķ��������ᴩ���㽨����������Щ����ģ�ͣ��ܹ�ģ�͡����ģ�͡�Դ����Ͳ����������ҵľ������и��������Ļ�����֯�����Ƕ��ڵĸ�����Щ�����������ǵ�����ʱ�Ÿ��£��������ܱ�����Щ��������������֮���һ���ԡ�ӵ������һ������ĺô��ǵ���������仯��ʱ���ܹ���������Ӱ���������Ϊ��֪������仯��Ӱ�쵽ϵͳ����Щ���档���ǣ�������ϵͳֻ�м�������Ϥ��������Ҫ���ϵͳ��Ч�ʣ���ô���������۵��������Ǽĸ�����Ŀ�����ԱԤ�����ֱ仯�ijɱ������ҵľ��飬������ôһ������ɸ��پ������ǵò���ʧ����ʹ����ר�ŵĹ�����ʵ�֣���Ȼ���������������Ĵ��ۡ��������Ŀ�����˽⽨�����־���ijɱ������棬�������Լ��������Ͼ����ɸ���Ҳ�����ĵ���Ӧ����һ��ҵ�������һ��Ӧ�������������ľ����� Types of Requirements ������������Է�Ϊ���ࣺ�����Ժͷǹ����ԡ�һ�������ԣ�behavioral�������������û���κ�ϵͳ�������û����� user interface issues������������ʹ��ϵͳ���÷� usage����ϵͳ�������һ��ϵͳ���ܣ�ҵ����� business rules����һ���ǹ����ԣ�non-behavioral������������ϵͳ�е�ij�������������ر�����Щ�Ϳ����ԡ���ȫ�ԡ������ԡ������ԡ������ԡ��ɿ����йصļ�����������һ����Ҫ����������Ժͷǹ���������֮��Ľ�����ʱ�������һ���������ݴ洢�ٶ�����ֵ���������������ƺ���������һ��ʵ�ʵļ���ָ�꣬�������ֿ��Է�ӳΪ�û��������Ӧʱ�䣬���ϵ�������Ժ�DZ���÷������ʿ��ƣ���������˭�����ض���Ϣ�� ��������һ���ǹ�������������ͨ������Ϊ��һ����ȫ�������������ǹ�����������һ���С�����������������û�б�Ҫ���ۣ��д��µĸ���ͺ��ˡ��ؼ��Ļ�����Ҫ�����������������������㽫����ִ����࣬�ߺߣ�Who Care�� Potential Requirements Artifacts ���������кü��ֲ�ͬ���������ͣ�Ҳ�����е�һЩ����ȫ�����ʺ������Ŀ�����⣬ÿһ�ֽ�ģ�����������ij����Ͷ̴�������Ҫ���պü�������ģ�������ḻ�����еĹ����䡣��1�ܽ���һЩͨ�õ�����ģ������������ϸ��������һƪ���ģ�Artifacts for Agile Modeling.�����۵ġ������ʹ�üĹ������������ֲ�ͬ���͵������ģ�͡�������ʹ�ü���������Ҫ�Կ��Բο�ǰ���С�ڣ�Some Philosophy���� ��ס��Ҫ��һ�㣺��Ȼ�����ʹ�ø��ָ����Ĺ������ռ��������Ⲣ������ζ������һ����Ŀ��Ҫȫ��������Щ������ԭ���˽����ģ�͡��������ں��ʵ�ʱ����ȥ�˽����ʹ����Щ����������������棬�������ʵ�������ú��ʵĹ�������˵������ �����������·��Ĺ��̻�Ӱ�칤����ѡ�����ҵ���ҳ���ҽ���AMӦ�ú������������������ʹ�ã�����XP����UP����Щ�����������������ڡ��²�Ĺ���ͨ����ƫ����ʹ��ijһ������������XP���زĺ�UP���������������������ģ��ʱ�����Ҫ���ǵ�һ�����⡣�ⷽ���ϸ�ڿ��Բο��ҵ�����AM and XP �� AM and UP�� A Usage-Centered Approach ������Ӧ�����������ݵİ취����������ģ���أ�����������һ�����ӣ�������������㽫ͨ��SWA Online case study.ѧϰ���Ϊ����ģ����������ʽ��ʼ֮ǰ����һЩ����������Ҫ���˽⡣��һ����Ϊ��ƪ���µĽ��㼯��������ģ�ϣ�����������һЩ���ۣ����漰������ģ�͡��ܹ�ģ�͡����ģ��֮��Ķ��������ǵ�����֮�У���������£����ǻ���ʱ�Ľ������۲��ص����ǵ�����������ͬʱ�������ص����µĵ��������������������Ե���Ϊ�����ģ����������ģ�������Ľ�ģ���Ľ��dz�ģ�����ڶ������Dz��õķ���ֻ���ڶ����ݷ����е�һ�֡���ס��AMֻ��һ����ʵ��Ϊ�����ķ��������������ֶ����������ϸ֦ĩ�ڣ�����������ô��������ô���ķ�����������������ܹ�ʵ��Ŀ�ġ����õ��ģ��һ����ָ��һЩ��ѡ�ķ����������Լ���Ҫ����һ�ſ��ŵ��ġ�����������SWA Online�ŶӲ��õĹ�����Ҫ�Ǹ���EUP��Enterprise Unified Process���ƶ��ģ����Թ���Ҳ��������Ϊ����������ģ�л����ʹ����������XP�����У��زĻ֮ᷴռ�о��Ե����ơ�һ���ģ��������Ҳ���õ��ģ���AM and XPһ���У�����Ҳ��ϸ�����˴�XP�Ĺ۵����������ְ�����ѧϰ�����ģ�����д��һ�ڵ�ʱ���ҷ���������������ô����ʵ�������Ƿ�����������Χ��һ�������������ӡ���������ʵ�ϣ���ֻ�Ǹ������ڹ�����������ϵͳ�еľ�����������ġ����壬������ð����̷ֳ��������������ǣ���ʼ����Σ�IRUF initial requirements up front����ϸ�ڽ�ģ�Ρ� The Initial Requirements Up Front (IRUF) Phase ��ʼ����η����������Ŀ���������ڵĿ�ʼ�Σ�����RUP��Rational Unified Process����Kruchten, 2000���б���Ϊ�����ĽΣ�XP�еĵ�һ�ε���֮ǰ����IRUF����������Ҫ��Ŀ�꣺��������һ���߲�IJ���϶���ϵͳ��Χ��������Ϳ����ҳ�ϵͳ�ı߽������Ϊϵͳ����߽������������������ں���Ŀ�����Ա��ȡ��һ���������֤�����˳�����С�IRUF�ο��ܷdz��Ķ̣�Ҳ��ֻ�м���Сʱ���ر���������ں�������ͬһ�������������ڶ�ϵͳ�ܿ�Ĵ����һ�µ���������������ô�����Ļ��������Ҳ�п��ܻ���չ�����������������ڡ��ر�������Ҫ�ٿ����͵Ľ�ģ���飬��������IRUF�εļ���Ŀ�ꡣ�������������ص������ �� �ܳ���һЩ���͵���Ŀ�������ܻ�ﵽ���졣 �� ��Ҫ�ܶ�����ڲ��룬�Ա�֤���������������Χ�ġ� �� ͨ���DZȽ���ʽ�ģ����������������϶࣬������Ŀ���ڼ�Ƚϲ���Ϥ��Ե�ʣ� �� ����һЩ������Ա���ر�����ϣ������Ŷ��ܹ��������ϵͳ��ʱ�� ϵͳ�ķ�Χ������һ����������������SWA Online��������������ǾͿ��Լ�����Ϊ��ͨ����������˿����۲�Ʒ�����Ǹ�����һЩ����䡰����ʵ�Ķ���������IJ�Ʒ���۸������Ŀͻ��������˾ɿͻ����¿ͻ�����ϵͳ��ΧҲ����ʹ��һ��������ģ����������ģ����ʵ���ϵͳ�����Ӧ���廷��������ʹ������ͼ����������ͼ5����Ҳ����ʹ��DFDͼ����ʾ����ͼ4�������ֵ�DFDͼͨ������Ϊ0��DFDͼ�����˽�ϵͳ�ķ�Χ����Ҫ��������Ͳ�����һЩ����ϵͳ��Χ�����ù�����һ���������Ե�̫���������ǿ�����Ϊ�������������Ŀͻ�����ľ�������ķ����������ͻ����ϣ�ͬ��������Ҳ������Ϊ������������Ʒ�������������֡����Ҫ�������������������֮���Ҫһ�����ߵĵ������硣��Ҳ���ܻᷢ����ķ�Χʱ�̶��ڱ仯�����������Ŀ������Ҫ�������������ұ���Ҫ����ӵ���仯�� 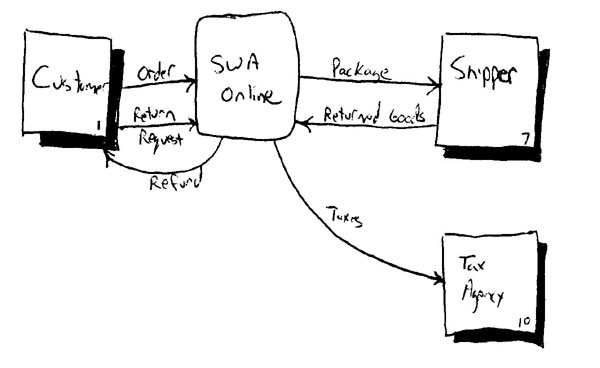 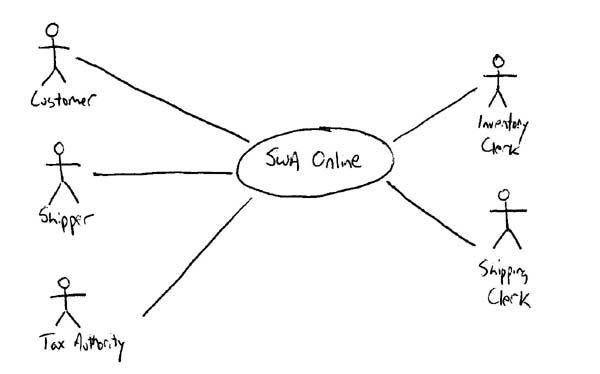 ��ʲô������ϵͳ��Χ����õĹ����أ�������䣬DFDͼ����������ͼ����ȡ������ľ���������������dz�ֱ�ӣ����Dz���ͼ��ô������ͼ4��DFDͼ��ʾ��ͼ��������ϵͳ���Ա����ⲿʵ�壬����֯���ˣ�����ϵͳ����Щ�ⲿʵ����Ȼ����ϵͳ��һ���֣��������Ƕ���ϵͳ�йأ���ʵ��֮����߶α�ʾ����֮��Ĺ�ϵ�����ַ��������ô����Ǻ��������ʾ��ϵͳ���ⲿ�������Ϣ����Ҫ������ϸ�ڡ�ͼ5������ͼ����������һ�����ϵͳ����ͬ������������ϵͳ���Ա��Ǻ�ϵͳ������ϵ�Ľ�ɫ����֯���ˣ������ַ�������Ҫ������ͬʱ���������ⲿ���ڲ��ģ���ϵͳ�����Ľ�ɫ����������DFDͼ����ֻ������ϵͳ�ⲿ�ķ��档��������Ҫȱ��������������ϵͳ�ͽ�ɫ�Ľ�����ϸ�ڡ������Ǹò�������ͼʾ�أ���Ȼ���ŵ�����ȱ�㣬�����Dz���Ӧ�����߶������أ�Hmmmm���ⲻ������ӹ���뷨���ˡ�һ���ȽϺõİ취��ֻ��һ��ͼ�����ƹ�������ͼ�õĵط��ó����ϳ�һ��ͼ����������ͼ6�е�������ע��������������ڲ�ʵ�������ʵ������Ϸ�����һ����I���ı�ǣ��������Լ��ķ�����⣬�һ��������������ÿ��ʵ�塣���������ֱ���ֹ������ô����������ɶ����һ������ÿ��ʵ����������Ψһ�ģ������Ļ��������ܹ������ֱ�ǵ������ˡ���Ҳ���Ժ�������DFDͼ��ʹ������ͼ�ķ��š���ʹ������ͼ�Ĺ�������ʾDFDͼ������������Ϊ�ҵ���Ŀ���ڱȽ�ƫ��DFDͼ��������Ҳ�������ǵ�ƫ�á���ס���ԭ����ģҪ����Ŀ���ԡ������������˽�������ڣ�ѡ��һ�����ʺ����ǵĹ����� ��Ҫ���´��ƹ�����һ��ʵ������������0����DFDͼ�в�Ҫ�����ڲ�ʵ�壬��������������У��㿪ʼ�ھ�ϸ�ڵ�ʱ����ͱ���Ҫ�����ڲ�ʵ�塣����ͼ6�����������ͱ������ٻ�һ��ͼ����˵�ˣ�û�в����ϸ�Ľ�ģ���ԣ�����Ҳ������ʧ�����ǵģ����ֹ۵���ҵ���һ��ԭ�����ñ��Ľ�ģ����ì�ܣ��������������ҿ���ͬʱ���Ϳ�����ά���ķ��á����Ա���Ϊһ��������Ļ����ҵ���֯�о�Ҫ���¿�����Щ���ˡ� 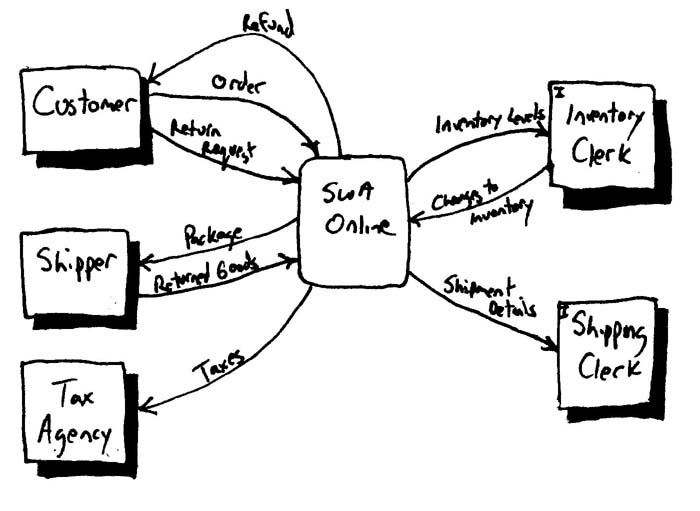 Ϊ���ܹ�ȷ��ϵͳ�ĸ߽������ұȽ������ڲ���һ�������÷�Ϊ�������ķ����������Ҫע������Ҫ����������û����ʹ�����ϵͳ�����ϡ��ҵľ�������ң����������������˵��һ���dz���Ч�ķ��������뿴����������û����ʹ�����ϵͳ���������˽⣬��������˵���ϵͳ�ܹ��Ľ����ǵĹ�����ʽ�����������췽ҹ̷�����ַ�����������������֯�ڲ�ʹ�õ���ҵӦ�ã�����������֯�Ŀͻ�ʹ�õ���ҵ�����������ڰ�װ���۵���������CASE���ߺ����ִ������������������ݲֿ�Ŀ�����������COTS��commercial off the shelf����ϵͳ���ɣ���SAP��R/3ϵͳ��Oracle�Ľ���ϵͳ������һ�����ݲֿ�İ����У������һ���������ռ������������г�������Ҫ�����ݲֿ��д洢��data element��data entity�����ַ����������ƺ���û��ʲô���ף���������㲻֪����Щ������������ʲô�ģ���ͺ��Ѷ����Ŭ���ų����ȼ�����Ҳ���˽������Ŀ���ڵ�����ҪЩʲô����COTSϵͳ�İ����У���Ҳͬ����Ҫ��������������������Ҫʹ�õ�����������1���г�����Щ���������ܡ�ʹ����ڡ��������زģ����Ƿdz��õ�ѡ����ʵ����ʹ������ʵĹ��������һ�ѡ������������SWA Onlineϵͳ����ΪSWA��˾��ʹ��EUP��Ϊ�������̵���Ҫ������������ѡ������������Ӧ������״�����������ѡ��XP��Ϊ��Ҫ���������زľͳ�Ϊ����ʵĹ�����ͬ���������Ҫ������FDD��Feature Driven Development��(Coad, Lefebvre, DeLuca, 1999) ������Ҳ�������ѡ�� ͼ7�����Һ��ҵ���Ŀ����һ���ĸ߽�����ͼ�����ڰװ��ϻ��ģ�Ȼ�������ִ����ġ����Ǹ���������ͼ����Ϊ���ͼ����أ�����ζ���������ֹ�ʵ�֣�Ҳ�����Զ���ʵ�֡��ǵģ��������ǼDz�Ʒ���ˡ���������ƺ����ɡ����ز�Ʒ���ϡ�����һЩ�������ҵ���Ŀ������Ϊ����ʶ����Ǹ������С�������Ŭ������������ͼ����أ�������ʵ�������ϵͳ����������ijһ�ּܹ��У���SWA Online��������һ�������������Ľ�����������Ի�ʱ���ϵͳ�����������������������Ϊһ�������ļ������͵�ϵͳ��û�кܴ�ļ�ֵ�ġ���ס���ԭ����������ڵ�Ͷ����������������ģ��Ŭ�������ܹ��ṩ������ֵ�Ĺ����ϡ� ��IRUF �Σ�����Ӧ�������ļ�һЩ��ֻҪ�ܹ�������ÿ����������Ҫ��Ϳ����ˡ��㲻��Ҫ�����ʱ��������ϵͳ������ϸ�ڣ��������Ҫ�˽�ϵͳӦ����ɵ������һ��������ʶ���Լ�ϵͳ���ʼ�ķ�Χ��ÿ�������ͽ�ɫ�ĸ�Ҫ��������������Ŀ���������㲻��Ҫ��IRUF��̫�����룬�����ֻ��Ҫʶ���3��4���������Ѿ��㹻�ˡ������ԭ��Ŀ�Ľ�ģ������������Ϳ��Խ������IRUF�Σ����������е�ϸ�ڽ�ģ�������ǰ��ʶ�������������ν�ģ��ʵ�֡�ע�⣬��ϲ���UP����Ŀ���ԣ��������µ�˳�����һ������XP����Ŀ�������ȻһЩ�� ��ͼ7�У�����Կ�����������ģͼ��Ӧ����UML�İ��ͣ�stereotype��<<Include>>��Ȼ����The Object Primer 2/e (Ambler, 2001a) һ���У����Ƽ�˵���ְ���������ڷ�����������ʹ�ã���������������ϵͳ����ͼ�е�ʱ��������Ϊ���ְ���ͨ����ӳ��һ�ּܹ�������Ƶ����⣬���Ⲣ��������ε�����ͼ��Ҫ���ĵġ������Ǿ仰�����ϸ����ѭ�������ԣ��������Ҳ������˶�������֮�֡��������ͼ����Ȥ֮���������Ұ����е�һЩ�������õĹ�ͨ������ȡ�������ⷴӳ����ͬʱ����������ͷ�����������������ʵ�� �������Ŀ�����д��һ�µ��������һ��֪�����ѡ��ⷽ��ľ�����Ϣ���Բ����ҵ�overcome the common challenges to requirements efforts��ÿ������Ŀ���ڶ��в�ͬ�ı�������ͬ��Ȩ���𣬲�ͬ��ѡ��Ҫ���ڲ�ͬ����֮����һ���ԣ�ÿ���˶�Ҫ��ʶ�������Ե���ʵ���������Ƕ�ϵͳ����Ҫ�����������˵���������ù�ͬ��һ��Ŀ��Ŭ�������ۺ�ʱ���������ŶӺ�����ʱ�����ǻ���һ�������������⡣��ʱ�����ǻ��ڰװ���д��ÿһ���˵����⣬�����˶����Կ�����Щ���⣬��������Щ���⡣��������ʵ�������������ǵIJ�𣬲��������ṩһ���������۵�ƽ̨����ʱ�һ��һ������Ӱװ���ȥ������Ϊ������������ʶ�����������Dz���Ҫ������Ҫ�Բ��ܹ������������Ⲣ�еġ���Ҳϲ����һЩ����������֮�仭��ֱ�ߣ�������ҵ�ע�������Ἧ�е�����������ʹ���ر����ɫ����Ҳ�ܹ��ﵽ����Ч���� ��С�������۸߽�ʹ�������ʱ���˿���ϵͳ�ļ��������ҵ���������ǻ�Ҫʶ�����ص�ҵ���������ơ���IRUF�Σ���Ӧ�á���š�һЩϵͳ�������ƺͼ�������ͨ���������Ǽ�¼�ڰװ�Ļ��ͼ�ϣ���ȡ�㹻����Ϣ�Թ�����̽�������ϸ�ڵ�ʱ���˽�����Ŀ���Ǿ����ܿ�Ľ���IRUF�Σ�����Ա��⻨�ѹ����ʱ��Ѱϸ�ڡ�������ڳ�ʼ����ξͿ�ʼ����ϸ�ڣ���ͻ����������Ե�Σ��֮�У����ʱ����˷��ڷ���ϸ�����档��ס���ԭ���������������ҪĿ�ꡱ����Ҫ����ľ��������ڽ���ģ�ͺ��ĵ����棬���ϵ���������������һ��ʲô���ӡ��ٸ����ӣ���SWA Online�����Ŀ�ij�ʼ��������У��ҵ���Ŀ����Ҳ��ʶ���һЩ�Ͷ�����ص�ҵ���������ƣ�����δ��ij�����͵Ļ����Щ��������������װ�����ޣ�����װ���Ĺ���Ҫ������ʲôʱ����������Щ����ͻ����˰�����¼���������Լ��ڰװ��������Ƭ�ϣ�������Ҷ����Կ����� ��������һ������Ҫ�Ĺ۵㣺��ģ�����ǽ���ʽ�ġ�ÿ���˶�Ҫ���롣�տ�ʼһ���о���Ľ�ģ��Ҫ��һЩ����������һЩ���������̼��������˽⡣���֡��̼������ܷdz������ף����������������װ�ǰ��������̸�۵����ݣ���ҵ������������д��һ��������Ƭ�����ڼ�ʱ���ϼ�¼һ�ſ��ܵı�������Ҫ�����ݡ���������Ϥ�����ֽ�ģ���˳���ڶ�AM�ġ����ڻ������롱��ʵ��������һ�µ��˽�֮����ͻᷢ���㲻����Ҫ���̼��������ˡ��ǰ����κ���һ��ʼ���Ầ�ߣ���Ҫij����ʽ�ġ��̼������������ԡ� ������Ŷ���Ϊ��ǰ�İ汾ʶ�������ʱ�����ǿ��ܻ���ʶ���δ���İ汾�е�һЩ�����һЩδ����һЩDZ������Ҫ�Ź���Щ��Ϣ�����������ڼȲ�ϣ���������ʱ����̽��Ҳ��ϣ���������Ϊ��ȥ��Ӧ��ЩDZ�����������Ӵ�Ȼ������Щ��Ϣ����ļܹ����а����ģ�DZ�������������ڲ�ͬ�ļܹ���ѡ������ļܹ������������Change cases��Bennett, 1997; Ambler, 2001a����������DZ�������ĵ����ļ������������ͼ8�м���SWA Online�����������������ȷ����Χ��һ���ص���ʶ�����Щ�ڷ�Χ֮�ڣ���Щ�ڷ�Χ֮�⡣���Ұ�DZ������ʶ��Ϊһ����������������ʾ������������������Ŀ��Χ֮��ġ���������ڼܹ������е���Чʹ�÷�������ۿ��Բο��ҵ�Agile Architecture essay. ���: ���Ž��뱱���г� ������: �dz����� Ԥ��ʱ��: 12-18 ���� Ӱ��: �� ������Ҫ֧�ּ��ô��ī����Ŀͻ�����Ҫ�µ������˹�ϵ �� ��Ҫ������ص�˰��˰�� �� ���ڷ�������͵���ϰ�ף�����Щ�г��ϵIJ�Ʒ���ۿ��ܲ�һ�� �� ֧�ֶ������Ե�վ�㣨���ô�Ĺٷ�������Ӣ��ͷ��ī����Ĺٷ�������������� ���: ���������Ʒ���������֣���Ƶ���鼮���� ������: �dz����� Ԥ��ʱ��: 6-12 ���� Ӱ��: �� ������������̲�ͬ �� ��Ҫ֧��һЩ��Ʒ��������Ȩ �� �����Ʒ�������ƣ���Ч���ޡ����������� ͼ8. SWA Online�������������. ��ô�����ö��ٵ��ĵ�����¼���˽����Ŀ��Χ����Ŀ�ĸ߽������أ���������Agile Documentation�н�������������þ����ˡ���SWA Online�İ����У��һὨ��һ��HTMLҳ�棬������ͼ6�е�������ͼ��ͼ7�е�����ͼ���Լ�һ����Щ�ڷ�Χ֮�ڣ���Щ�ڷ�Χ֮����б������ڸ߽������ĵ����һ����������ת¼Ϊ���ִ�������ʽ�����text�ļ�����Ϊ�����ڽ���ģ��ϸ����ʱ��������չ���ǡ������Ǵ��Ϊ�����ĵ�����ʽ���ڹ����Ͳ�������������Ϊ��ҵ��������ƣ���������ͱ������������������Ƭ����ϣ�������ܹ�����������ʽ����Ϊ������ϸ�ڽ�ģ�����л��ᾫ�����ǡ��������ȷʵ��Ҫ�����ǿ�����ʱ��֮������Ϊ������Ҫ�ĸ�ʽ������������ŶӾͿ���Ѹ�ٵĽ���ϸ�ڽ�ģ�ĽΣ�Ȼ�����ʵ�֡���Ϊ���DZ����˴�����ʵ������Ҫ���ĵ������ر�����һЩҵ�������ʵ�Ǵ��ģ���������֪�����ǵ���α֮ǰ������д���ĵ���Ŭ���Ͷ����ˡ��� Detailed Requirements Modeling һ��IRUF�εijɹ���ϵͳ�ķ�Χ�߽����õ��ϣ������ҪΪ��������ų������������ڲ����ſ������� Starting an Iteration �ڵ�����ʼ��ʱ�����е�������Ҫ���䵽ÿ��������Աͷ�ϡ���һ��XP����Ŀ�У�������Ա�������Ը��ԭ��ǩ��ij���زģ�����Կ�����������̲�ͣ���ظ���ֱ�����ε����������زĶ��Ѿ���ɡ�����һ��UP��Ŀ�У��ŶӵĹ����������ܺ�XP�еIJ�࣬��������Ŀ����������ָ�ɸ����˻����Ŷӡ��Ȳ����Ƿ�������ľ�����ڣ��������Ŷ�/��Կ����߶��ԣ��������ڵ����������Ҫʵ����������Ҫ���ĵĵ�һ����������˽���Ŀ������Ҫ��ϸ�ڣ�������ЩҲ��Ҫ������ģ�� ���������ֻ�����������������ڵ�����ʼʱ���������Ŷӣ� 1. ���ε�������Ⱥ�齨ģ. �������ַ����������Ŷӣ�������Ŀ���ڣ���ͬ����̽Ѱ����ϸ�ڣ���������������ǰϵͳ��֧����Щ�����ǵ���ĵ������ԼΪ2�ܣ����ֽ�ģ����ij��ȱ�����1��Сʱ������ij��ȾͿ����ˡ������ĵ�����Ƚϳ�������4��6�ܣ��������Ҫ��һ��ʼͶ��һ�����ʱ�䡣��Ҫ���ó���һ���ʱ��������������Dz�û�к�ʵ�ʵ����塣���ַ������ŵ�����ڱ��ε����и��Ŷ���������һ�������Ը�������Ǵ����������Լ��Ĺ������ռ��������Ŷӳ�Ա��������������ڳ���ȷ��һ�����÷����ļ��ʾʹ�������ˡ����ַ�����ȱ��������ֻ�����ڽ�С���Ŷӣ��ر�������10�˵��Ŷӣ������������еĸ�����˵ʵ�������˷���ʱ�䣬��Ϊ�����������˶��������Ŀ�ĸ������档ע�⣬һ�����ε����ij�ʼ��ģ������ɣ��������Ŷ���Ȼ��Ҫ���ʵ�ʱ�佨���������йص�ϸ��ģ�ͣ���Ȼ����Ҳ�����ڱ��ε����еġ� 2. ���ŶӶ�������ģIndividual subteams model their requirement(s). ��һЩ�����ŶӲ�������������Ⱥ�齨ģ�����Ǽ��ø������Ŷ�������ʵ�֡��������������ÿ������֮��ûʲô��ϵ��������ϵ������ʱ��������Ա��ѭ�����������ơ���Collective Ownership����ʵ������ͬ��һ������������Ϲ��������ַ������ŵ����������Ŷ��ܹ��ڵ���һ��ʼ��Ѹ�ٵĽ���ϸ�������С�Ȼ������Ҳ��һЩȱ�㡣���ȣ�������ܽ�����Ҳ���������ŶӶ������ͼ��㶩�������йص����飨����һ���ŶӼ���˰�ʣ�һ���ŶӼ����ۿۣ���������Ϳ���ð�ظ������ķ��ա�����ܲ�����һ�������ص����⣬��Ϊÿ�����ŶӶ�Ӧ��Ҫ�ܹ��˽��������ŶӵĹ�����������Ҫ��ͬ��������Σ�����Ŷ���Ҫ�Ƚ϶��ʱ�����̶�ʵ��Ը�����ٴΣ���һ��ʼ��Ҫ������Ŀ���ڵġ�����Ȩ������Ϊ���е����ŶӶ���Ҫ��Ŀ���ڵġ��ס����¹��� During An Iteration һ��������˵���һ��ʼ�Ĺ���������ŶӾͿ�ʼһ�����µĹ�������ģ�����롢���ԡ������Ͳ�������������Σ�����Ҫ�������Ŀ�������ֵ�����ģ�Ĺ�����̽����Щ�����ϸ�ڡ�ʵ���ϣ���Щ������Ӧ�ø���ȷ��˵�ǽ�ģ���飬��������������ж��뿪���ֻ��顣��Щ����ͨ������һ�֡����ˡ��ķ�ʽ���еģ��μӵ�����Ҳ���࣬����ɸ����������Ŀ������ŶӺ�һ����������Ŀ������ɡ����֡����ˡ��Ļ���Ŀ�ʼҲ����������һЩ����ʽ�Ļ������磬��Сǿ���ܲ��ܻ�һЩʱ�����һ�¹˿����������������ģ��� ������������SWA Online��Ŀ������Щϸ������ģ�ģ����ȣ�����������������Ը���ʵ�ֱ��ε����еġ�����������������ʵ�ֶ�������ʹ�����������Ķ������̣�����ȫ���̵�һ���֡�Ŀǰ���Dz���ʵ�ֲ��ҹ��ܡ�������쳣������˰�ʼ��㡢�ۿۼ��㡣���������������̱����dz�Ϊ������֮·������Ϊ��ֻ��ʵ����������Ķ������̡���ѡ���������˵�����ִ��ʱ�ķ��������̣���������������У����ͻ�Ҫ��Ļ������������Ǹ���ѡ���̡�Ȼ�����DZ��ε�����Ŀ��ֻ��Ҫʵ��������ġ�����֮·�������������������������Ŷ�ʵ�ֻ������Ժ�ĵ�����ʵ�֡� ��ͼ9��ʾ���������ĵ�һ���������Ҫʹ��������������������ͬʱ���ǻ�Ҫ��������������йص�UIԭ�ͣ���ͼ2�������Dz��еĽ��������������Ϊ����֮��û�й�ϵ�ģ������������û�����¶�������UIԭ�Ͷ�����SWA Onlineϵͳ���û���������������Ϊ��ע�⣬�����ڵڶ��е����ˡ�������Ʒ�����������ͼ7�е�<<Include>> ���͵�Ӧ����һ�µġ���������������ʵ�ֵġ����������������е���������ܣ����������������ǵķ�Χ֮�ڣ��������Dz���ʵ������ܡ�Ϊ�˲�Ӱ���������ǿ���ֱ��ʹ��һ�ݲ��ҵ�����ֵ�嵥�����������Ŀ�ij�Щʱ���ʵ�֣����������ڡ�����ס�������������������������⣬���ǻ�Ҫע���������Ҳû���漰�κεļ������⣬��Щ�������ǻ��ڷ�������ƽο��ǡ���������ֻ����Ҫ�˽ⶩ���Ļ������̣���Щ���DzŻῼ��ʵ�֣�����ֻ�Ǽ����Ӻ�������������һЩ���ε����������̣�����˰�ʺ��ۿ۵ļ��㡣 1. ���ͻ��¶�����ʱ�������Ϳ�ʼ�� 2. �ͻ�������Ʒ��ʹ��������������Ʒ�� 3. �ͻ�ѡ����Ʒ�����Ӷ���� 4. �ͻ���д������Ʒ�������� 5. ϵͳ�Զ�����ÿ����Ʒ��С�ƣ����ۡ��������� 6. �ͻ��ظ�2��5����ֱ����ɶ����� 7. �ͻ���ɶ���. 8. �ͻ��ṩ���ǵ����ͺ�����Ϣ�������������绰�͵�ַ. 9. ϵͳ����ÿ����ƷС�ƣ��õ������ܼۡ� 10. ϵͳ���ݼ��㶩��˰�ʵ���ҵ������㶩����Ӧ��˰� 11. ϵͳ���ݼ����ۿ۵���ҵ������㶩�����ۿۡ� 12. ϵͳ��ʾ˰����ۿ� 13. ϵͳ����˰���ȥ�ۿۣ��õ��������ܼۡ� 14. ϵͳ��ʾ������Ҫ 15. �ͻ���鶩���� 16. ϵͳ����ִ�ж���������������ִ�ж������� ��17. ϵͳΪ�ͻ�����һ�ű��ζ������վݡ� ��������ϵͳUI�����������ʵ�֣����ǻ���ѡ�����ü�ʱ���ͻ��ͼ�����������������HTML�༭������Ϊֽ��Ƚ��е��ԣ�����������������������Ҫ�ġ�������ոտ�ʼ��ʱ��������Ҫ����������ӡ��ƶ����Ƴ�UIԪ�أ�����������Ҫ�ܹ�֧�����ֹ������ԵĹ��ߡ��Ժ�һ��ֽ�ϵ������ȶ����������ǾͻὫ֮ת�Ƶ�HTML�༭���У���ʱ�����ǾͿ��������������UI�Թ���Ŀ�������ۡ���ʱ�ͺá� ����������У�����Ҫ���ؼ���AM��ʵ�������������д������ģ�͡�����Ϊ����ͬʱҪ����������UIԭ�͵Ĺ�������������һ��ģ������Ϊÿ���ŶӶ�������������Ա������һ�����ṩ�������Ŀ���ڣ���������ģ�͡���������ͼ2�о�������һ�����¶������ļ�ģ�ͣ�ͼ9�������������������ݡ�ʵ����������ӣ���Ϊ�����ṩ����������ҵ����������ϸ�ڡ����ǻ�Ҫ��ѭ��Ӧ�ú��ʵĹ�������ҵ�����Ҫ����������ʾ������Ӧ���õ�����ҵ�����������������ܻ�����˵�����㶩���ܼۡ��������̾���һ��ҵ������������Ϊ���硰���㶩��˰��͡����㶩���ۿۡ������ĵ�����������Ƭ�������ң��û����������Ҳ��Ҫ���ض��Ĺ�����UIԭ�ͣ���¼�����⣬������ǻ�Ҫ������������ģ���Ǹ���ģ�ͣ����Ļ���ϸ���ۣ�Ҳ�DZ���ġ����ǻ���ѭ��ʵ��������������������������UIԭ�ͼ����ظĶ�����������UIԭ�������ӹ��ܵ�ʱ��������ʶ������ҲҪ����Ӧ�����������������Ӧ����ʵ����ʹ����Ĺ��ߡ�����ֽ��������UIԭ�ͣ��ðװ��������������� ���������Ѿ������ǵĽ�ģ�����������ˣ������ֻ�ǻ���30��60���ӵ�ʱ�䣩�����ǻ������������ģ�͡����ģ�ͣ�һֱ������ʵ�֡��������ǻ����ٻ�һЩʱ����������Ŀ�ŶӸոմ�ɹ�ʶ�ĸ���ģ�͡��ұȽ��������ø���ģ�;����ܵļ�����ʹ��CRC��Ƭ������ͬ����ͼ3�п����ģ���ΪCRC��Ƭ����������Ҳ������Ϊ���������ܡ����Dz������Ա�ʾ����������е���Ҫʵ�壬���ܹ���ʾʵ��֮��Ĺ�ϵ���������ݺ���Ϊ���㻹����һ����������ģ�͵Ĵ���ѡ��ʹ��UML����ͼ��ʹ����ͼ�ĺô����ܹ�������/ʵ��֮���ϵ��ϸ�ڣ���������Ժͽ�ɫ��CRC��Ƭ��ʵ����֮���ϵ��ͨ����������ʽʵ�ֵġ�����������ͼ����������CRC��Ƭ����Ϊ���������ܣ�ͬʱҲ��Ϊ���ĸ����ԣ�ʹ�����ڵIJ���̶Ƚ��͡���ͳ������ģ��Ҳ�������ڸ��ģ��������ͨ�����ڽṹ�Լ����Ļ���֮�У���UML��ͼһ�����������ڣ���Ҳ�������⡣ ��Ȼ�������Ľ�ģ�����ڶ̶�һ��Сʱ֮�ھͿ�����ɣ�����Ҳ���Խ���Ľ�ģ�����ֳɶ��СƬ�ϣ��ȼ�����������ͷ���к���ص�UI��ʵ�ֲ��ֵĹ��ܣ�Ȼ���ڻع�ͷ�����������ʣ�µIJ��֡����ַ���ͬ�������ã��������ÿ��У�Ҳ���Բ������ַ����� ����һ���������Ҫ��������˽���һ�εĵ�������Ҫ���ϵĽ���������ʱ������Ҫ�ص�����ģ�Ĺ����С����㿪ʼʵ�֡������������Ĺ���ʱ����Ҫָ������ʵ������ܵľ���ϸ�ڲ����Ƿdz��˽⡣��������嶩����Ʒ���������ơ�����������µ������������Ҫ���¶�����ܹ��ơ������ŵ�δ����ij��������ִ�С�Ҳ��������Ͷ���ûʲô��ϵ������ͻ���Ҫ�����ṩ���ǵ��ʻ���������Ϣ�������ζ����δ���ĵ�������Ҫ�����µ����� |