| 3.1 处理服务器响应
XMLHttpRequest对象提供了两个可以用来访问服务器响应的属性。第一个属性respo-
nseText将响应提供为一个串,第二个属性responseXML将响应提供为一个XML对象。一些简单的用例就很适合按简单文本来获取响应,如将响应显示在警告框中,或者响应只是指示成功还是失败的词。
第2章中的例子就使用了responseText属性来访问服务器响应,并将响应显示在警告框中。
3.1.1 使用innerHTML属性创建动态内容
如果将服务器响应作为简单文本来访问,则灵活性欠佳。简单文本没有结构,很难用JavaScript进行逻辑性的表述,而且要想动态地生成页面内容也很困难。
如果结合使用HTML元素的innerHTML属性,responseText属性就会变得非常有用。innerHTML属性是一个非标准的属性,最早在IE中实现,后来也为其他许多流行的浏览器所采用。这是一个简单的串,表示一组开始标记和结束标记之间的内容。
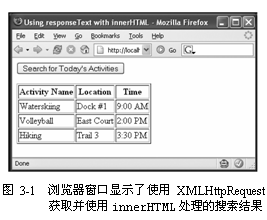
通过结合使用responseText和inner-HTML,服务器就能“生产”或生成HTML内容,由浏览器使用innerHTML属性来“消费”或处理。下面的例子展示了一个搜索功能,这是使用XMLHttpRequest对象、其responseText属性和HTML元素的innerHTML属性实现的。点击search(搜索)按钮将在服务器上启动“搜索”,服务器将生成一个结果表作为响应。浏览器处理响应时将div元素的innerHTML属性设置为XMLHttpRequest对象的response-Text属性值。图3-1显示了点击search按钮而且在窗口内容中增加了结果表之后的浏览器窗口。
第2章的例子只是将服务器响应显示在警告框中,这个例子的代码与它很相似。具体步骤如下:
1. 点击search按钮,调用startRequest函数,它先调用createXMLHttpRequest函数来初始化XMLHttpRequest对象的一个新实例;
2. startRequest函数将回调函数设置为handleStateChange函数;
3. startRequest函数使用open()方法来设置请求方法(GET)及请求目标,并且设置为异步地完成请求;
4. 使用XMLHttpRequest对象的send()方法发送请求;
5. XMLHttpRequest对象的内部状态每次有变化时,都会调用handleStateChange函数。一旦接收到响应(如果readyState属性的值为4),div元素的innerHTML属性就将使用XMLHttpRequest对象的responseText属性设置。
代码清单3-1显示了innerHTML.html。代码清单3-2显示了innerHTML.xml,表示搜索生成的内容。
代码清单3-1 innerHTML.html
<!DOCTYPE html PUBLIC "-//W3C//DTD
XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html
xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Using
responseText with innerHTML</title>
<script
type="text/javascript">
var xmlHttp;
function createXMLHttpRequest()
{
if (window.ActiveXObject) {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
else if (window.XMLHttpRequest) {
xmlHttp = new XMLHttpRequest();
}
}
function startRequest()
{
createXMLHttpRequest();
xmlHttp.onreadystatechange = handleStateChange;
xmlHttp.open("GET", "innerHTML.xml", true);
xmlHttp.send(null);
}
function handleStateChange()
{
if(xmlHttp.readyState == 4) {
if(xmlHttp.status == 200) {
document.getElementById("results").innerHTML
= xmlHttp.responseText;
}
}
}
</script>
</head>
<body>
<form action="#">
<input type="button" value="Search for Today's Activities"
onclick="startRequest();"/>
</form>
<div id="results"></div>
</body>
</html>
代码清单3-2 innerHTML.xml
<table border="1">
<tbody>
<tr>
<th>Activity Name</th>
<th>Location</th>
<th>Time</th>
</tr>
<tr>
<td>Waterskiing</td>
<td>Dock #1</td>
<td>9:00 AM</td>
</tr>
<tr>
<td>Volleyball</td>
<td>East Court</td>
<td>2:00 PM</td>
</tr>
<tr>
<td>Hiking</td>
<td>Trail 3</td>
<td>3:30 PM</td>
</tr>
</tbody>
</table>
使用responseText和innerHTML可以大大简化向页面增加动态内容的工作。遗憾的是,这种方法存在一些缺陷。前面已经提到,innerHTML属性不是HTML元素的标准属性,所以与标准兼容的浏览器不一定提供这个属性的实现。不过,当前大多数浏览器都支持innerHTML属性。可笑的是,IE是率先使用innerHTML的浏览器,但它的innerHTML实现反而最受限制。如今许多浏览器都将innerHTML属性作为所有HTML元素的读/写属性。与此不同,IE则有所限制,在表和表行之类的HTML元素上innerHTML属性仅仅是只读属性,从一定程度上讲,这就限制了它的用途。
3.1.2 将响应解析为XML
你已经了解到,服务器不一定按XML格式发送响应。只要Content-Type响应首部正确地设置为text/plain(如果是XML,Content-Type响应首部则是text/xml),将响应作为简单文本发送是完全可以的。复杂的数据结构就很适合以XML格式发送。对于导航XML文档以及修改XML文档的结构和内容,当前浏览器已经提供了很好的支持。
浏览器到底怎么处理服务器返回的XML呢?当前浏览器把XML看作是遵循W3C DOM的XML文档。W3C DOM指定了一组很丰富的API,可用于搜索和处理XML文档。DOM兼容的浏览器必须实现这些API,而且不允许有自定义的行为,这样就能尽可能地改善脚本在不同浏览器之间的可移植性。
W3C DOM
W3C DOM到底是什么?W3C主页提供了清晰的定义:
文档对象模型(DOM)是与平台和语言无关的接口,允许程序和脚本动态地访问和更新文档的内容、结构和样式。文档可以进一步处理,处理的结果可以放回到所提供的页面中。
不仅如此,W3C还解释了为什么要定义标准的DOM。W3C从其成员处收到了大量请求,这些请求都是关于将XML和HTML文档的对象模型提供给脚本所要采用的方法。提案并没有提出任何新的标记或样式表技术,而只是力图确保这些可互操作而且与脚本语言无关的解决方案能得到共识,并为开发社区所采纳。简单地说,W3C
DOM标准的目的是尽量避免20世纪90年代末的脚本恶梦,那时相互竞争的浏览器都有自己专用的对象模型,而且通常都是不兼容的,这就使得实现跨平台的脚本极其困难。
W3C DOM和JavaScript
W3C DOM和JavaScript很容易混淆不清。DOM是面向HTML和XML文档的API,为文档提供了结构化表示,并定义了如何通过脚本来访问文档结构。JavaScript则是用于访问和处理DOM的语言。如果没有DOM,JavaScript根本没有Web页面和构成页面元素的概念。文档中的每个元素都是DOM的一部分,这就使得JavaScript可以访问元素的属性和方法。
DOM独立于具体的编程语言,通常通过JavaScript访问DOM,不过并不严格要求这样。可以使用任何脚本语言来访问DOM,这要归功于其一致的API。表3-1列出了DOM元素的一些有用的属性,表3-2列出了一些有用的方法。
表3-1 用于处理XML文档的DOM元素属性
|
属性名 |
描述 |
|
childNodes |
返回当前元素所有子元素的数组 |
|
firstChild |
返回当前元素的第一个下级子元素 |
|
lastChild |
返回当前元素的最后一个子元素 |
|
nextSibling |
返回紧跟在当前元素后面的元素 |
|
nodeValue |
指定表示元素值的读/写属性 |
|
parentNode |
返回元素的父节点 |
|
previousSibling |
返回紧邻当前元素之前的元素 |
表3-2 用于遍历XML文档的DOM元素方法
|
方法名 |
描述 |
|
getElementById(id)
(document) |
获取有指定惟一ID属性值文档中的元素 |
|
getElementsByTagName(name) |
返回当前元素中有指定标记名的子元素的数组 |
|
hasChildNodes() |
返回一个布尔值,指示元素是否有子元素 |
|
getAttribute(name) |
返回元素的属性值,属性由name指定 |
有了W3C DOM,就能编写简单的跨浏览器脚本,从而充分利用XML的强大功能和灵活性,将XML作为浏览器和服务器之间的通信介质。
从下面的例子可以看到,使用遵循W3C DOM的JavaScript来读取XML文档是何等简单。代码清单3-3显示了服务器向浏览器返回的XML文档的内容。这是一个简单的美国州名列表,各个州按地区划分。
代码清单3-3 服务器返回的美国州名列表
<?xml version="1.0" encoding="UTF-8"?>
<states>
<north>
<state>Minnesota</state>
<state>Iowa</state>
<state>North Dakota</state>
</north>
<south>
<state>Texas</state>
<state>Oklahoma</state>
<state>Louisiana</state>
</south>
<east>
<state>New York</state>
<state>North Carolina</state>
<state>Massachusetts</state>
</east>
<west>
<state>California</state>
<state>Oregon</state>
<state>Nevada</state>
</west>
</states>
在浏览器上会生成具有两个按钮的HTML页面。点击第一个按钮,将从服务器加载XML文档,然后在警告框中显示列于文档中的所有州。点击第二个按钮也会从服务器加载XML文档,不过只在警告框中显示北部地区的各个州(见图3-2)。
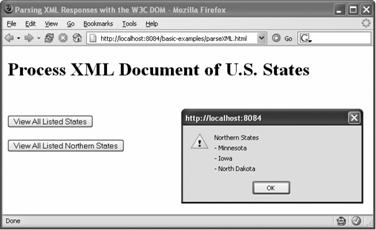
图3-2 点击页面上的任何一个按钮都会从服务器加载XML文档,并在警告框中显示适当的结果
代码清单3-4显示了parseXML.html。
代码清单3-4 parseXML.html
<!DOCTYPE html PUBLIC "-//W3C//DTD
XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Parsing XML Responses with
the W3C DOM</title>
<script type="text/javascript">
var xmlHttp;
var requestType = "";
function createXMLHttpRequest() {
if (window.ActiveXObject)
{
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
else if (window.XMLHttpRequest)
{
xmlHttp = new XMLHttpRequest();
}
}
function startRequest(requestedList)
{
requestType = requestedList;
createXMLHttpRequest();
xmlHttp.onreadystatechange
= handleStateChange;
xmlHttp.open("GET",
"parseXML.xml", true);
xmlHttp.send(null);
}
function handleStateChange() {
if(xmlHttp.readyState
== 4) {
if(xmlHttp.status == 200) {
if(requestType == "north") {
listNorthStates();
}
else if(requestType == "all") {
listAllStates();
}
}
}
}
function listNorthStates() {
var xmlDoc = xmlHttp.responseXML;
var northNode = xmlDoc.getElementsByTagName("north")[0];
var out = "Northern
States";
var northStates =
northNode.getElementsByTagName("state");
outputList("Northern
States", northStates);
}
function listAllStates() {
var xmlDoc = xmlHttp.responseXML;
var allStates = xmlDoc.getElementsByTagName("state");
outputList("All States
in Document", allStates);
}
function outputList(title, states) {
var out = title;
var currentState =
null;
for(var i = 0; i <
states.length; i++) {
currentState = states[i];
out = out + "\n- " + currentState.childNodes[0].nodeValue;
}
alert(out);
}
</script>
</head>
<body>
<h1>Process
XML Document of U.S. States</h1>
<br/><br/>
<form action="#">
<input type="button" value="View All Listed States"
onclick="startRequest('all');"/>
<br/><br/>
<input type="button" value="View All Listed Northern
States"
onclick="startRequest('north');"/>
</form>
</body>
</html>
以上脚本从服务器获取XML文档并加以处理,它与前面看到的例子很相似,不过前面的例子只是将响应处理为简单文本。关键区别就在于listNorthStates和listAllStates函数。前面的例子从XMLHttpRequest对象获取服务器响应,并使用XMLHttpRequest对象的responseText属性将响应获取为文本。listNorthStates和listAllStates函数则不同,它们使用了XMLHttpRequest对象的responseXML属性,将结果获取为XML文档,这样一来,你就可以使用W3C
DOM方法来遍历XML文档了。
仔细研究一下listAllStates函数。它首先创建了一个局部变量,名为xmlDoc,并将这个变量初始化设置为服务器返回的XML文档,这个XML文档是使用XMLHttpRequest对象的responseXML属性得到的。利用XML文档的getElementsByTagName方法可以获取文档中所有标记名为state的元素。getElementsByTagName方法返回了包含所有state元素的数组,这个数组将赋给名为allStates的局部变量。
从XML文档获取了所有state元素之后,listAllStates函数调用outputList函数,并在警告框中显示这些state元素。listAllStates方法将迭代处理state元素的数组,将各元素的相应州名逐个追加到一个串中,这个串最后将显示在警告框中。
有一点要特别注意,即如何从state元素获取州名。你可能认为,state元素会简单地提供属性或方法来得到这个元素的文本,但并非如此。
表示州名的文本实际上是state元素的子元素。在XML文档中,文本本身被认为是一个节点,而且必须是另外某个元素的子元素。由于表示州名的文本实际上是state元素的子元素,所以必须先从state元素获取文本元素,再从这个文本元素得到其文本内容。
outputList函数的工作就是如此。它迭代处理数组中的所有元素,将当前元素赋给currentState变量。因为表示州名的文本元素总是state元素的第一个子元素,所以可以使用childNodes属性来得到文本元素。一旦有了具体的文本元素,就可以使用nodeValue属性返回表示州名的文本内容。
listNorthStates函数与listAllStates是类似的,只不过增加了一个小技巧。你只想得到北部地区的州,而不是所有州。为此,首先使用getElementsByTagName方法获取north标记,从而获得XML文档中的north元素。因为文档只包含一个north元素,而且getElementsByTagName方法总是返回一个数组,所以要用[0]记法来抽出north元素。这是因为,在getElementsByTagName方法返回的数组中,north元素处在第一个位置上(也是惟一的位置)。既然有了north元素,接下来调用north元素的getElementsByTagName方法,就可以得到north元素的state子元素。有了north元素所有state子元素的数组后,再使用outputList方法在警告框中显示这些州名。
3.1.3 使用W3C DOM动态编辑页面
Web最初只是作为媒介向各处分发静态的文本文档,如今它本身已经发展为一个应用开发平台。遗留的企业系统通常通过纯文本的终端部署,或者作为客户―服务器应用部署,这些遗留系统正在被完全通过Web浏览器部署的系统所取代。
随着最终用户越来越习惯于使用基于Web的应用,他们开始有了新的要求,需要一种更丰富的用户体验。用户不再满足于完全页面刷新,即每次在页面上编辑一些数据时页面都会完全刷新。他们想立即看到结果,而不是坐等与服务器完成完整的往返通信。
你已经了解了解析服务器发送的XML消息是多么容易。W3C DOM提供了一些属性和方法,使你能轻松地遍历XML结构,并抽取所需的数据。
前面的例子对于服务器发送的XML响应并没有做多少有用的事情。在警告框中显示XML文档的值没有太大的实际意义。你真正想做到的是让用户享有丰富的客户体验,不再遭遇一般Web应用中常见的连续页面刷新问题。页面连续刷新不仅使用户不满意,还会浪费服务器上宝贵的处理器时间,因为页面刷新需要重新构建整个页面的内容,而且会不必要地使用网络带宽来传送刷新的页面。
当然,最好的解决办法是根据需要修改页面上已有的内容。如果页面上大多数数据没有改变,则不应刷新整个页面,只需要修改页面中信息有变化的部分。
以往,在Web浏览器的限制之下,这一点很难做到。浏览器只是一个工具,它解释特殊的标记(HTML),并根据一组预定的规则显示这些标记。Web以及Web浏览器原来只是为了显示静态的信息,如果不以新页面的形式从服务器请求新的数据,这些信息不会改变。
除了一些例外情况,当前的浏览器都使用W3C DOM来表示Web页面的内容。这样做可以确保在不同的浏览器上Web页面会以同样的方式呈现,同时在不同的浏览器上,用于修改页面内容的脚本也会有相同的表现。Web浏览器的W3C
DOM和JavaScript实现越来越成熟,这大大简化了在浏览器上动态创建内容的任务。原来总是要苦心积虑地解决浏览器间的不兼容性,如今这已经不太需要。表3-3列出了用于动态创建内容的DOM属性和方法。
表3-3 动态创建内容时所用的W3C DOM属性和方法
|
属性/方法 |
描述 |
|
document.createElement(tagName) |
文档对象上的createElement方法可以创建由tagName指定的元素。如果以串div作为方法参数,就会生成一个div元素 |
|
document.createTextNode(text) |
文档对象的createTextNode方法会创建一个包含静态文本的节点 |
|
<element>.appendChild(childNode) |
appendChild方法将指定的节点增加到当前元素的子节点列表(作为一个新的子节点)。例如,可以增加一个option元素,作为select元素的子节点 |
|
<element>.getAttribute(name)
<element>.setAttribute(name,
value) |
这些方法分别获得和设置元素中name属性的值 |
|
<element>.insertBefore(newNode,
targetNode) |
这个方法将节点newNode作为当前元素的子节点插到targetNode元素前面 |
|
<element>.removeAttribute(name) |
这个方法从元素中删除属性name |
|
<element>.removeChild(childNode) |
这个方法从元素中删除子元素childNode |
|
<element>.replaceChild(newNode,
oldNode) |
这个方法将节点oldNode替换为节点newNode |
|
<element>.hasChildnodes() |
这个方法返回一个布尔值,指示元素是否有子元素 |
关于浏览器的不兼容性
尽管当前Web浏览器中W3C DOM和JavaScript的实现在不断改进,但还是存在一些特异性和不兼容性,这使得应用DOM和JavaScript进行开发时很是头疼。
IE的W3C DOM和JavaScript实现最受限制。2000年初,一些统计称IE占据了整个浏览器市场95%的份额,由于没有竞争压力,Microsoft决定不完全实现各个Web标准。
这些特异问题大多都能得到解决,不过这样做会让脚本更是混乱不堪而且不合标准。例如,如果使用appendChild将<tr>元素直接增加到<table>中,则在IE中这一行并不出现,但在其他浏览器中却会显示出来。对此的解决之道是,将<tr>元素增加到表的<tbody>元素中,这种解决办法在所有浏览器中都能正确工作。
关于setAttribute方法,IE也有麻烦。IE不能使用setAttribute正确地设置class属性。对此有一个跨浏览器的解决方法,即同时使用setAttribute("class",
"new- ClassName") 和setAttribute("className","newClassName")。另外,在IE中不能使用setAttribute设置style属性。最能保证浏览器兼容的技术不是<element>.setA-
ttribute("style, "font-weight:bold;"),而是<element>.style.cssText
= "font
- weight:bold;"。
本书中的例子会尽可能地遵循W3C DOM和JavaScript标准,不过如果必须确保大多数当前浏览器的兼容性,可能也会稍稍偏离标准。
下面的例子展示了如何使用W3C DOM和JavaScript来动态创建内容。这个例子是假想的房地产清单搜索引擎,点击表单上的Search(搜索)按钮,会使用XMLHttpRequest对象以XML格式获取结果。使用JavaScript处理响应XML,从而生成一个表,其中列出搜索到的结果(见图3-3)。
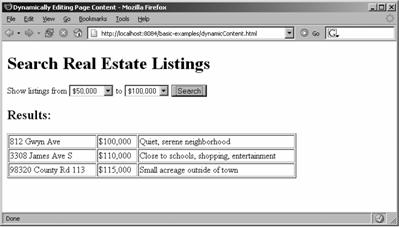
图3-3 使用W3C DOM方法和JavaScript动态创建搜索结果
服务器返回的XML很简单(见代码清单3-5)。根节点properties包含了得到的所有property元素。每个property元素包含3个子元素:address、price和comments。
代码清单3-5 dynamicContent.xml
<?xml version="1.0" encoding="UTF-8"?>
<properties>
<property>
<address>812 Gwyn Ave</address>
<price>$100,000</price>
<comments>Quiet, serene neighborhood</comments>
</property>
<property>
<address>3308 James Ave S</address>
<price>$110,000</price>
<comments>Close to schools, shopping, entertainment</comments>
</property>
<property>
<address>98320 County Rd 113</address>
<price>$115,000</price>
<comments>Small acreage outside of town</comments>
</property>
</properties>
具体向服务器发送请求并对服务器响应做出回应的JavaScript与前面的例子是一样的。不过,从handleReadyStateChange函数开始有所不同。假设请求成功地完成,接下来第一件事就是调用clearPreviousResults函数,将以前搜索所创建的内容删除。
clearPreviousResults函数完成两个任务:删除出现在最上面的“Results”标题文本,并从结果表中清除所有行。首先使用hasChildNodes方法查看可能包括标题文本的span元素是否有子元素。应该知道,只有hasChildNodes方法返回true时才存在标题文本。如果确实返回true,则删除span元素的第一个(也是惟一的)子节点,因为这个子节点表示的就是标题文本。
clearPreviousResults的下一个任务是在显示搜索结果的表中删除所有行。所有结果行都是tbody节点的子节点,所以先使用document.getElementById方法得到该tbody节点的引用。一旦有了tbody节点,只要这个tbody节点还有子节点(tr元素)就进行迭代处理。每次迭代时都会从表体中删除childNodes集合中的第一个子节点。当表体中再没有更多的表行时,迭代结束。
搜索结果表在parseResults函数中建立。这个函数首先创建一个名为results的局部变量,这是使用XMLHttpRequest对象的responseXML属性得到的XML文档。
使用getElementsByTagName方法来获得XML文档中包含所有property元素的数组,然后将这个数组赋给局部变量properties。一旦有了property元素的数组,可以迭代处理数组中的各个元素,并获得property的address、price和comments。
var
properties = results.getElementsByTagName("property");
for(var i = 0; i < properties.length;
i++) {
property = properties[i];
address
= property.getElementsByTagName("address")[0].firstChild.nodeValue;
price = property.getElementsByTagName("price")[0].firstChild.nodeValue;
comments
= property.getElementsByTagName("comments")[0].firstChild.nodeValue;
addTableRow(address,
price, comments);
}
下面来仔细分析这个循环,因为这正是parseResults函数的核心。在for循环中,首先得到数组中的下一个元素,并把它赋给局部变量property。接下来,对于你感兴趣的各个子元素(address、price和comments),分别获得它们的节点值。
请考虑address元素,这是property元素的一个子元素。首先在property元素上调用getElementsByTagName方法来得到单个address元素。getElementsByTagName方法返回一个数组,不过因为你知道有且仅有一个address元素,所以可以使用[0]记法来引用这个元素。
沿着XML结构继续向下,现在有了address标记的引用,你需要得到它的文本内容。记住,文本实际上是父元素的一个子节点,所以可以使用firstChild属性来访问address元素的文本节点。有了文本节点后,可以引用文本节点的nodeValue属性来得到文本。
采用同样的办法来得到price和comments元素的值,并把各个值分别赋给局部变量price和comments。再将address、price和comments传递给名为addTableRow的辅助函数,它会用这些结果数据具体建立一个表行。
addTableRow函数使用W3C DOM方法和JavaScript建立一个表行。使用document.cre-
ateElement方法创建一个row对象,之后,再使用名为createCellWithText的辅助函数分别为address、price和comments值创建一个cell对象。createCellWithText函数会创建并返回一个以指定的文本作为单元格内容的cell对象。
createCellWithText函数首先使用document.createElement方法创建一个td元素,然后使用document.createTextNode方法创建一个包含所需文本的文本节点,所得到的文本节点追加到td元素。这个函数再把新创建的td元素返回给调用函数(addTableRow)。
addTableRow函数对address、price和comments值重复调用createCellWithText函数,每一次向tr元素追加一个新创建的td元素。一旦向row(行)增加了所有cell(单元格),这个row就将被增加到表的tbody元素中。
就这么多!你已经成功地读取了服务器返回的XML文档,而且动态创建了一个结果表。代码清单3-6显示了这个例子完整的JavaScript和可扩展HTML代码。
代码清单3-6 dynamicContent.html
<!DOCTYPE html PUBLIC "-//W3C//DTD
XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Dynamically Editing Page
Content</title>
<script type="text/javascript">
var xmlHttp;
function createXMLHttpRequest() {
if (window.ActiveXObject)
{
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
else if (window.XMLHttpRequest)
{
xmlHttp = new XMLHttpRequest();
}
}
function doSearch() {
createXMLHttpRequest();
xmlHttp.onreadystatechange
= handleStateChange;
xmlHttp.open("GET",
"dynamicContent.xml", true);
xmlHttp.send(null);
}
function handleStateChange() {
if(xmlHttp.readyState
== 4) {
if(xmlHttp.status == 200) {
clearPreviousResults();
parseResults();
}
}
}
function clearPreviousResults() {
var header = document.getElementById("header");
if(header.hasChildNodes())
{
header.removeChild(header.childNodes[0]);
}
var tableBody = document.getElementById("resultsBody");
while(tableBody.childNodes.length
> 0) {
tableBody.removeChild(tableBody.childNodes[0]);
}
}
function parseResults() {
var results = xmlHttp.responseXML;
var property = null;
var address = "";
var price = "";
var comments = "";
var properties = results.getElementsByTagName("property");
for(var i = 0; i <
properties.length; i++) {
property = properties[i];
address = property.getElementsByTagName("address")[0].firstChild.nodeValue;
price = property.getElementsByTagName("price")[0].firstChild.nodeValue;
comments = property.getElementsByTagName("comments")[0]
.firstChild.nodeValue;
addTableRow(address, price, comments);
}
var header = document.createElement("h2");
var headerText = document.createTextNode("Results:");
header.appendChild(headerText);
document.getElementById("header").appendChild(header);
document.getElementById("resultsTable").setAttribute("border",
"1");
}
function addTableRow(address, price,
comments) {
var row = document.createElement("tr");
var cell = createCellWithText(address);
row.appendChild(cell);
cell = createCellWithText(price);
row.appendChild(cell);
cell = createCellWithText(comments);
row.appendChild(cell);
document.getElementById("resultsBody").appendChild(row);
}
function createCellWithText(text) {
var cell = document.createElement("td");
var textNode = document.createTextNode(text);
cell.appendChild(textNode);
return cell;
}
</script>
</head>
<body>
<h1>Search Real Estate Listings</h1>
<form action="#">
Show listings from
<select>
<option value="50000">$50,000</option>
<option value="100000">$100,000</option>
<option value="150000">$150,000</option>
</select>
to
<select>
<option value="100000">$100,000</option>
<option value="150000">$150,000</option>
<option value="200000">$200,000</option>
</select>
<input type="button"
value="Search" onclick="doSearch();"/>
</form>
<span id="header">
</span>
<table id="resultsTable" width="75%"
border="0">
<tbody id="resultsBody">
</tbody>
</table>
</body>
</html>
上一页 首页
下一页 |